
Koncepcja Internetu Rzeczy (IoT) opierała się pierwotnie na stosunkowo prostej architekturze: miliony czujników gromadziły surowe dane fizyczne, które następnie były bezustannie przesyłane do scentralizowanej chmury obliczeniowej w celu analizy i podjęcia decyzji. W miarę jak globalna liczba wdrożonych urządzeń IoT zbliża się w 2026 roku do prognozowanych 30 miliardów, ten chmurowy model napotkał na fundamentalne ograniczenia infrastrukturalne, ekonomiczne oraz fizyczne. Ciągła transmisja surowych strumieni wideo czy danych pomiarowych generuje kolosalne zapotrzebowanie na przepustowość pasma, wprowadza nieprzewidywalne opóźnienia sieciowe i naraża krytyczne lub poufne dane na ataki w kanale transmisyjnym.
Odpowiedzią na te wyzwania jest Tiny Machine Learning (TinyML) – technologia umożliwiająca uruchamianie modeli uczenia maszynowego bezpośrednio w systemach mikroprocesorowych. Wymaga to jednak zmierzenia się z istotnymi ograniczeniami. Mikrokontrolery klasy IoT dysponują zazwyczaj pamięcią statyczną (SRAM) w przedziale od kilkudziesięciu do maksymalnie kilkuset kilobajtów, ograniczoną ilością pamięci Flash oraz szczątkową mocą obliczeniową, często przy całkowitym braku jednostek zmiennoprzecinkowych (FPU). Co więcej, systemy te nierzadko operują na zasilaniu bateryjnym, gdzie całkowity budżet energetyczny mierzony jest w mikrowatach, a od oprogramowania wymaga się działania w reżimie czasu rzeczywistego (z wykorzystaniem systemów RTOS lub architektury bare-metal).
Początkowo, zmagając się z tymi barierami, inżynierowie implementowali jedynie najprostsze algorytmy: klasyfikatory liniowe, proste drzewa decyzyjne czy algorytmy k-najbliższych sąsiadów (k-NN). Jednak lata 2025–2026 to okres wyraźnego przejścia w stronę tzw. Tiny Deep Learning (TinyDL). Dzięki innowacyjnym metodom kompresji, na mikrokontrolerach wdrażane są obecnie złożone architektury konwolucyjne (CNN) czy warianty oparte na mechanizmach uwagi (attention mechanisms), które potrafią dokonywać złożonej inferencji z opóźnieniami rzędu kilkunastu milisekund. Urządzenie brzegowe zyskuje tym samym autonomię decyzyjną – nie musi już wysyłać do chmury pełnego zestawu danych pomiarowych; wystarczy, że prześle uzyskane lokalnie wyniki obliczeń.

Ewolucja architektur sprzętowych: ARM Cortex-M, RISC-V i koprocesory NPU
Aby sprostać wymaganiom TinyML, producenci półprzewodników musieli przeprojektować klasyczne architektury mikrokontrolerów. Konieczne było znalezienie kompromisu pomiędzy minimalizacją poboru prądu (szczególnie w trybach uśpienia) a zapewnieniem odpowiedniej liczby operacji na sekundę (GOPS) niezbędnych do przeliczania rozległych macierzy wag sieci neuronowych. Rywalizacja toczy się obecnie pomiędzy dominującym ekosystemem ARM a dynamicznie rosnącą, otwartą architekturą RISC-V, przy jednoczesnym wprowadzaniu sprzętowych akceleratorów neuronowych (NPU).
Architektura ARM Cortex-M
Rodzina procesorów ARM Cortex-M stanowi rynkowy fundament dla systemów embedded. Jej sukces w zastosowaniach AI wynika z dojrzałości ekosystemu narzędziowego oraz świetnej gęstości kodu gwarantowanej przez zbiór instrukcji Thumb-2 (mieszane instrukcje 16- i 32-bitowe, kluczowe przy ograniczonej pamięci Flash).
Architektura RISC-V
Chociaż ARM zapewnia stabilność rynkową, zamknięta natura i koszty licencyjne tej architektury stymulują innowacje w obrębie ekosystemu RISC-V. RISC-V, jako otwarty standard zestawu instrukcji (ISA), daje inżynierom i projektantom krzemu niespotykaną dotąd swobodę w modyfikowaniu sprzętu. Zamiast polegać na gotowym rdzeniu ogólnego przeznaczenia, projektanci mogą dodawać własne rozszerzenia wektorowe i macierzowe, idealnie skrojone pod nietypowe operacje matematyczne wymagane przez specyficzne sieci neuronowe.
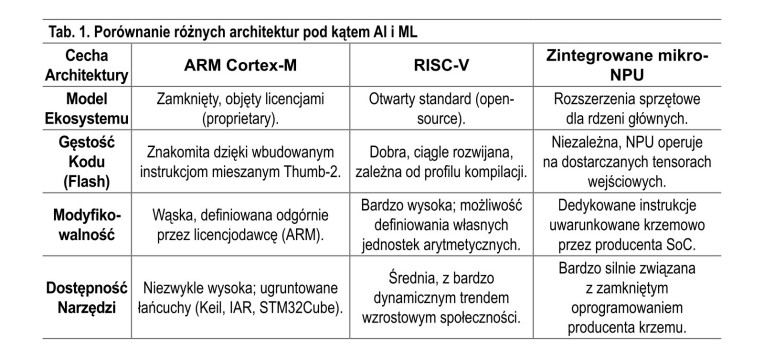
Akceleratory neuronowe (NPU) w strukturze mikrokontrolera
Niezależnie od wybranej architektury bazowej (ARM czy RISC-V), wyraźnym i nieodwracalnym trendem na rynku wdrożeń TinyML jest przechodzenie na układy heterogeniczne, parujące standardowy rdzeń wykonawczy ze sprzętowym koprocesorem neuronowym (NPU). Przetwarzanie wnioskowania na głównym procesorze MCU – wymagające wielokrotnego ładowania tych samych wag i aktywacji z głównej magistrali, połączone z sekwencyjnym obliczaniem iloczynów skalarnych – pochłania zbyt wiele cykli zegarowych i energii.
Techniki optymalizacji i kompresji modeli AI
Przeniesienie modeli AI (często opisywanych pierwotnie za pomocą setek milionów parametrów w języku Python za pośrednictwem bibliotek TensorFlow czy PyTorch) do pamięci fizycznej układu embedded (rzędu setek kilobajtów) wymaga zastosowania skutecznych metod kompresji. Modele takie przechodzą rygorystyczny cykl odchudzania, podczas którego konieczne jest zachowanie równowagi pomiędzy rozmiarami struktury a spadkiem ostatecznej skuteczności (tzw. zjawiskiem accuracy drop). Obecne stosuje się przede wszystkie dwie strategie optymalizacyjne: kwantyzację (quantization) oraz przycinanie (pruning).
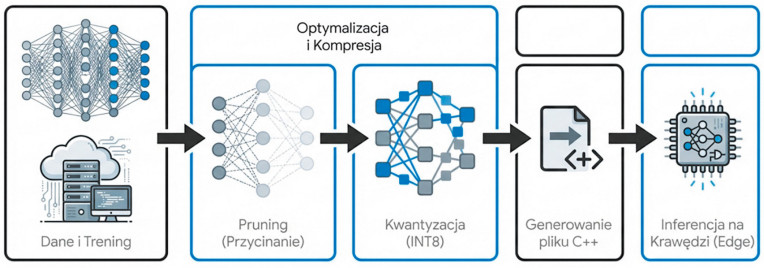
Kwantyzacja: Przesunięcie ku liczbom całkowitym
Tradycyjny trening sieci neuronowych dla zachowania maksymalnej dokładności poprawek gradientowych używa bardzo precyzyjnej, lecz kosztownej pamięciowo arytmetyki zmiennoprzecinkowej o wielkości 32 bitów (FP32). Kwantyzacja, stanowiąca fundament dla środowiska TinyML, transformuje te wartości na zbiór liczb całkowitych (z reguły 8-bitowych – INT8). Proces ten nie tylko czterokrotnie zmniejsza całkowity ślad pamięciowy (memory footprint) wag modelu, ale również zwalnia zasoby obliczeniowe procesora. Operacje na liczbach całkowitych zużywają mniej cykli procesora, redukując opóźnienia i wymagania wobec przepustowości szyny pamięci.
Wyróżnić można dwa najpopularniejsze podejścia do tego typu transformacji:
- Post-Training Quantization (PTQ): Sieć zostaje wyuczona w chmurze przy zastosowaniu pełnej precyzji FP32, a dopiero ostatecznie ulega statycznej kwantyzacji (zazwyczaj przy użyciu mapy przesunięcia z użyciem parametru skali oraz punktu zerowego). Choć jest to zabieg stosunkowo łatwy do przeprowadzenia, PTQ ma tendencję do wprowadzania zauważalnego obniżenia poprawności działania modelu (rzędu od kilku do kilkunastu procent) ze względu na "obcinanie" niuansów pomiędzy wagami.
- Quantization-Aware Training (QAT): Zdecydowanie bardziej zaawansowana metoda, w której sztucznie wygenerowany, symulowany szum dyskretyzacji dodaje się do samej procedury szkolenia w chmurze obliczeniowej. Zmusza to algorytm spadku gradientu do ciągłej aktualizacji wag z tolerancją na błędy obcinania zaokrągleń. QAT zapobiega nagłym załamaniom sprawności decyzyjnej po kompilacji, z reguły nie przekraczającym 1%.
Niekiedy stosuje się również podejście mieszane (mixed-precision quantization), w którym niektóre wrażliwe warstwy sieci pozostawia się na granicy INT16 lub FP16, a pozostałe obszary redukuje aż do 4 bitów (INT4). Interesujące wyniki uzyskuje się również przy wykorzystaniu Binarnych Sieci Neuronowych (Binary Neural Networks), w których aktywacje i wagi reprezentowane są jedynie pojedynczym bitem. Modele BNN pozwalają na tworzenie sieci neuronowych o rekordowo niskich rozmiarach.

Pruning (Przycinanie Sieci)
Drugą metodą kompresji jest zjawisko bezpośredniego fizycznego eliminowania redundancji, zwane przycinaniem (pruning). Analiza połączeń pomiędzy neuronami udowadnia, że wiele z nich ma marginalny, pomijalny wpływ na podejmowane decyzje klasyfikacyjne w sieci. Po ich programowym wymazaniu sieć przekształca się w formę tzw. macierzy rzadkiej (sparse matrix).
Inżynierowie mierzą się tu jednak z ograniczeniami architektury mikrokontrolerów. Wycinanie całkowicie losowych połączeń bez określonego wzorca strukturalnego (tzw. unstructured pruning) potrafi zredukować teoretyczny rozmiar modelu nawet o 90%. Niestety, operacje sprzętowe (szczególnie w jednostkach ALU MCU) niezbyt dobrze radzą sobie z sieciami o nieregularnej strukturze; system i tak zmuszony jest ładować pełne wektory zer w celu uniknięcia błędów dostępu w strukturze pamięci, co oznacza minimalne korzyści energetyczne mimo znacznego okrojenia modelu. Z tego powodu obecnie dużo bardziej popularny jest tzw. structured pruning (przycinanie strukturalne). Metoda ta eliminuje ze struktury programu całe bloki architektoniczne – konkretne kanały, wielowymiarowe rzędy czy zbędne filtry konwolucyjne. Usunięcie pełnych wymiarów umożliwia zmniejszenie liczby zintegrowanych operacji matematycznych z rodziny MAC (mnożenie z akumulacją, Multiply-Accumulate) od 50% aż do 70% na pojedynczy cykl, co skraca wprost proporcjonalnie rzeczywisty czas działania klasyfikatora na procesorze ARM, minimalizując straty predykcji poniżej bezpiecznej normy 2%.
Praktyka inżynierska pokazuje, że umiejętna optymalizacja oraz kompresja modelu AI pozwala zmniejszyć rozmiar sieci o wartości rzędu 70‒80% bez istotnego pogorszenia jakości jej pracy.
Fragmentacja ekosystemu
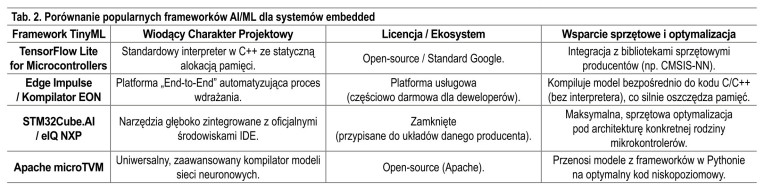
Optymalizacja samego algorytmu to tylko połowa sukcesu. Prawdziwym "wąskim gardłem" przy wdrożeniach TinyML pozostaje przełożenie gotowego, skompresowanego modelu AI na niskopoziomowy kod, który będzie natywnie działał na mikrokontrolerze i bezpośrednio współpracował z jego sprzętowymi sterownikami. Mimo ogromnego postępu, ekosystem narzędzi (toolchain) dla systemów embedded wciąż pozostaje silnie pofragmentowany. Wynika to ze zderzenia dwóch informatycznych światów. Z jednej strony mamy inżynierów elektroników i twórców systemów embedded, którzy programują w C/C++. Z drugiej strony stoją eksperci od przetwarzania danych (Data Scientists), którzy projektują i uczą sieci neuronowe wykorzystując wysokopoziomowego Pythona. Ten brak spójnego pomostu komunikacyjnego znacząco wydłuża czas wdrażania i zwiększa koszty projektów.
Standard De Facto: TensorFlow Lite for Microcontrollers (TFLM)
Obecnie najpopularniejszym środowiskiem uruchomieniowym, stanowiącym branżowy standard, jest TensorFlow Lite for Microcontrollers (TFLM). Został on napisany w C++ z myślą o urządzeniach z bardzo ograniczoną pamięcią. Kluczową cechą TFLM jest to, że całkowicie eliminuje dynamiczną alokację pamięci podczas działania sieci. Zamiast tego, programista rezerwuje statycznie określony blok pamięci (tzw. tensor arena). Algorytm wykonuje obliczenia bezpośrednio w tym buforze, nadpisując nieużywane już dane z poprzednich warstw. Z punktu widzenia projektanta systemów czasu rzeczywistego (RTOS) eliminuje to ryzyko wycieków oraz fragmentacji pamięci, gwarantując stabilność działania urządzenia.
Należy jednak pamiętać, że sam kod C++ w TFLM jest dość wolny i nie wykorzystuje w pełni możliwości sprzętowych mikrokontrolerów. Dlatego środowisko to zyskuje na wydajności dopiero po podłączeniu bibliotek zoptymalizowanych pod konkretny układ, takich jak CMSIS-NN dla rdzeni ARM Cortex-M. TFLM przekazuje wtedy obliczenia matematyczne do tej biblioteki, co pozwala na wykorzystanie sprzętowych instrukcji wektorowych (SIMD) i lepsze zarządzanie buforami. Takie połączenie potrafi przyspieszyć działanie sieci nawet dwukrotnie i znacząco zmniejszyć zapotrzebowanie na pamięć SRAM w porównaniu do kodu napisanego w czystym C++.

Rozwiązania No-Code
Zbudowanie zespołu, który równie dobrze zna się na projektowaniu obwodów i uczeniu maszynowym, bywa trudne. Odpowiedzią rynku na ten problem są zautomatyzowane platformy programistyczne typu End-to-End. Obecnie liderem jest tutaj Edge Impulse. Platforma ta pozwala w przeglądarce przygotować dane, wytrenować model, a następnie wygenerować gotową bibliotekę C/C++. Jej autorski kompilator (EON Compiler) tłumaczy model bezpośrednio na kod maszynowy, pomijając całkowicie warstwę interpretera. Znacznie oszczędza to miejsce w pamięci Flash i RAM.
Równolegle producenci mikrokontrolerów promują własne narzędzia zintegrowane z ich środowiskami programistycznymi (IDE). Przykłady to STM32Cube.AI od STMicroelectronics oraz eIQ firmy NXP. Rozwiązania te są ściśle dopasowane do konkretnych rodzin układów, pozwalając na wykorzystanie umieszczonych w nich akceleratorów sprzętowych. Na rynku pojawiają się także uniwersalne rozwiązania open-source, np. kompilator Apache microTVM, który potrafi przenosić modele z popularnych środowisk (PyTorch, Keras) na zoptymalizowany kod działający bezpośrednio na mikrokontrolerze.
Standaryzacja wydajności: MLPerf Tiny Benchmark
Wraz z rosnącą liczbą platform sprzętowych i narzędzi programistycznych, inżynierowie napotkali na trudności w obiektywnym porównywaniu wydajności układów. Brak ujednoliconych metod pomiaru zużycia energii czy czasu opóźnień utrudniał weryfikację deklaracji dostawców. Odpowiedzią na tę potrzebę są ustandaryzowane testy wydajnościowe (benchmarki), przeznaczone specjalnie dla systemów wbudowanych, takie jak pakiet MLPerf Inference: Tiny. Pozwalają one na obiektywne i powtarzalne mierzenie parametrów różnych architektur przy użyciu tych samych referencyjnych modeli klasyfikacyjnych oraz zestawów danych testowych. Co więcej, testy tego typu narzucają rygorystyczne wytyczne dotyczące metodologii pomiarów fizycznego zużycia energii przez platformy obliczeniowe.
Układy neuromorficzne
Tradycyjne mikrokontrolery, w tym również te wyposażone w akceleratory AI, działają w sposób synchroniczny. Oznacza to, że układ przetwarza dane w ustalonych cyklach zegara, zużywając stałą energię niezależnie od tego, czy rejestrowane przez czujniki sygnały niosą użyteczne informacje.
Alternatywnym podejściem, zyskującym na popularności, jest rozwój układów neuromorficznych, które naśladują sposób działania ludzkiego układu nerwowego za pomocą sieci impulsowych (Spiking Neural Networks – SNN). Układy tego typu wykorzystują przetwarzanie stymulowane zdarzeniami (Event-Based Processing). Zaimplementowane w nich cyfrowe neurony i synapsy działają w sposób asynchroniczny – pozostają w stanie głębokiego uśpienia, pobierając minimalną wartość prądu podtrzymania, i aktywują się tylko w momencie wykrycia konkretnego bodźca fizycznego (np. gwałtownej zmiany na matrycy wizyjnej lub w sygnale akustycznym). To sprawia, że pobór mocy ściśle koreluje z aktywnością środowiska, a nie z taktowaniem układu.
Dzięki takiej architekturze możliwe jest osiągnięcie zużycia energii na poziomie pojedynczych mikrowatów. Umożliwia to zasilanie układów dokonujących skomplikowanej ciągłej klasyfikacji przez wielokrotnie dłuższy czas w porównaniu z klasycznymi mikrokontrolerami. Systemy te stwarzają także obiecujące perspektywy dla rozwoju koncepcji sprzętowego uczenia bezpośrednio na urządzeniu docelowym (On-Device Learning). Umożliwia to ciągłą adaptację sprzętu do warunków panujących w jego bezpośrednim otoczeniu bez modyfikacji głównego kodu.

Zalety implementacji AI/ML na mikrokontrolerze
Przeniesienie algorytmów AI/ML na mikrokontrolery przynosi wymierne korzyści, które stanowią główny argument za upowszechnieniem tej technologii w rozwiązaniach produkcyjnych.
W klasycznym modelu chmurowym przesłanie danych wejściowych z czujnika, ich analiza na serwerze, a następnie odesłanie komendy zwrotnej często zajmuje relatywnie dużo czasu. W zastosowaniach przemysłowych i systemach automatyki – gdzie liczy się każdy ułamek sekundy – takie opóźnienia mogą być krytyczne. Przetwarzanie danych lokalnie, bezpośrednio na urządzeniu brzegowym, skraca czas reakcji układu sterowania, umożliwiając błyskawiczną interwencję w sytuacji awaryjnej.
Lokalna analiza to także oszczędność przepustowości łącza. Urządzenia końcowe wyposażone w modele zredukowane na przykład metodą kwantyzacji mogą filtrować informacje u źródła. Zamiast ciągłego wysyłania kosztownych, pełnowymiarowych obrazów z kamer przemysłowych lub pełnego spektrum dźwięku, mikrokontroler przesyła za pośrednictwem sieci komórkowej czy Wi-Fi jedynie metadane – na przykład krótkie alerty o wykrytej nieprawidłowości. Takie podejście drastycznie odciąża lokalną infrastrukturę sieciową.
Lokalne przetwarzanie to również odpowiedź na rosnącą potrzebę ochrony prywatności. Urządzenia noszone oraz sprzęt telemedyczny korzystające z technologii TinyML realizują zadania klasyfikujące, takie jak analiza tętna, bez udostępniania wrażliwych danych na zewnątrz, co znacząco zwiększa poziom bezpieczeństwa systemu oraz zaufania użytkowników.

Wyzwania w obszarze cyberbezpieczeństwa
Implementacja modeli AI na powszechnie dostępnych urządzeniach końcowych, które często pracują bez fizycznego nadzoru, rodzi specyficzne ryzyka w obrębie ochrony informacji.
Z inżynierskiego punktu widzenia największą barierą bezpieczeństwa jest moc obliczeniowa samych mikrokontrolerów. Niewielkie zasoby ograniczają możliwość zaimplementowania pełnej gamy klasycznych algorytmów zabezpieczających i szyfrujących pakiety bez jednoczesnego obciążania całego systemu. Fizyczna dostępność czujników otwiera przed atakującymi możliwość przeprowadzenia sprzętowych ataków inwazyjnych. Wprowadzając celowe zakłócenia sygnału zasilania lub sygnałów zegarowych (Fault Injection Attacks), napastnik potrafi wymusić błąd logiczny procesora, co może prowadzić do modyfikacji instrukcji skokowych w pamięci lub kradzieży algorytmów i modeli ukrytych wewnątrz komponentu. Zagrożeniem pozostają również ataki kanałem bocznym (Side-Channel Attacks), podczas których nasłuch promieniowania elektromagnetycznego oraz pomiary minimalnych wahań poboru prądu wokół urządzenia pozwalają, pod wpływem odpowiedniej stymulacji danymi, na powolną rekonstrukcję wag modelu.
Aby chronić sieci wbudowane przed tymi zagrożeniami, inżynierowie zabezpieczają architekturę stosując izolację pamięciową na poziomie układów scalonych, a komunikację z chmurą zabezpiecza się przy pomocy odpowiednich metod uwierzytelnienia, np. podczas procesu aktualizacji oprogramowania (OTA). Ponadto, wdraża się metody takie jak rozproszone środowisko uczenia (Federated Learning), gdzie węzły brzegowe podsyłają w szyfrowanych paczkach jedynie zagregowane uśrednione współczynniki aktualizujące model centralny, całkowicie blokując odczytywanie fizycznych sygnałów telemetrycznych zarejestrowanych ze swojego lokalnego środowiska, co wydatnie podnosi poziom prywatności sieci jako całości.
Podsumowanie
Rozwój technologii TinyML stanowi fundamentalny krok w ewolucji systemów wbudowanych. Przeniesienie zaawansowanych algorytmów sztucznej inteligencji bezpośrednio na energooszczędne mikrokontrolery zatarło granice między tradycyjną, prostą elektroniką a rozbudowaną analityką danych.
Możliwość przetwarzania danych lokalnie, bez polegania na ciągłym połączeniu z siecią internetową, pozwala budować systemy o wyższej niezawodności, mniejszych opóźnieniach operacyjnych i lepszej ochronie danych ze środowisk fizycznych. Systematyczna optymalizacja modeli matematycznych, coraz bardziej spójne środowiska kompilacyjne oraz powszechne pojawianie się sprzętowych koprocesorów wspierających operacji AI/ML powodują, że technologia ta stopniowo wkracza we wszystkie gałęzie elektroniki. Skuteczne wdrożenie tych koncepcji w systemach embedded wymaga zachowania interdyscyplinarnego podejścia inżynierskiego, które uwzględnia ograniczenia sprzętowe platform oraz wiedzę o projektowaniu oprogramowania analitycznego w skrajnie kompaktowych rozmiarach.
Damian Tomaszewski








