
Powszechna migracja w kierunków 32-bitowych procesorów o większych mocach obliczeniowych oraz większej ilości dostępnej pamięci umożliwiła znaczące rozbudowanie systemów mikroprocesorowych o nowe funkcje oraz zdolności. Wadą tego trendu jest wciąż zwiększający się rozmiar oraz złożoność kodu programu, co ma negatywny wpływ na jego niezawodność oraz bezpieczeństwo. Każda linijka kodu stanowi potencjalne źródło błędu lub lukę bezpieczeństwa, pozwalającą atakującym na nieautoryzowany dostęp do systemu. Od twórców oprogramowania oczekuje się dostarczania produktu wysokiej jakości, cechującego się bezpieczeństwem oraz niezawodnością. Aby sprostać tym wymaganiom, programiści muszą uważnie przyjrzeć się stosowanym przez siebie praktykom oraz technikom produkcji oprogramowania, gdyż jest to jeden z czynników o decydującym znaczeniu dla końcowej jakości tworzonego kodu. Uogólniając, błędy występujące w oprogramowaniu podzielić można na dwa typy:
- błędy w kodzie programu, takie jak np. próba odwołania się do niedozwolonego zakresu pamięci czy wyjście poza indeks zmiennej tablicowej. Tego typu problemy zlokalizować oraz rozwiązać można za pomocą narzędzi do statycznej analizy kodu źródłowego.
- błędy funkcjonalne, polegające na niezgodnym z zamierzeniami działaniem aplikacji. Do identyfikacji tego typu problemów konieczna jest gruntowna znajomość zasad działania oraz wymagań aplikacji, a także przeprowadzenie testów oprogramowania.
Wypracowanie efektywnych sposobów identyfikacji obu wymienionych rodzajów błędów przyniesie efekty w postaci tworzenia znacznie lepszego i bardziej niezawodnego oprogramowania.
Standaryzacja tworzonego oprogramowania
Popełnianie błędów jest nieuniknioną częścią procesu tworzenia oprogramowania – podobnie jak popełnianie literówek podczas pisania tekstów. I podobnie jak literówki, najprostsze i najbardziej podstawowe błędy wynikają przede wszystkim z pośpiechu piszącego i braku korekty oraz kontroli efektów jego pracy. Jednak wraz z rosnącą złożonością kodu w katalogu potencjalnych problemów pojawia się również cała paleta bardziej subtelnych i trudniejszych do wykrycia pomyłek. Mogą one wynikać nie tylko z błędnego zastosowanie narzędzia, jakim jest język programowania, ale także niedostatecznego lub błędnego zrozumienia istoty działania aplikacji, braku świadomości na temat powiązań pomiędzy jej poszczególnymi elementami czy też mechanizmów komunikacji pomiędzy nimi.
Jednym z najbardziej skutecznych sposobów na ograniczenie liczby błędów w kodzie jest standaryzacja tworzonego oprogramowania. Oznacza to przyjęcie zbioru reguł określających sposób tworzenia oprogramowania, wprost definiujących nakazy i zakazy związane z wykorzystywaniem pewnego typu konstrukcji i zwrotów, jak również porządkujących kod programu.
Według szacunków, około 80% błędów występujących w oprogramowaniu tworzonym w językach C oraz C++ generowane jest przez zaledwie około 20% konstrukcji i elementów tych języków. Oznacza to, że pewne elementy języka programowania, jak np. obsługa tablic, wskaźników czy też przekazywanie argumentów do funkcji, są odpowiedzialne za znaczącą większość wszystkich błędów występujących w oprogramowaniu tworzonym w tym języku. Standard tworzenia oprogramowania określa reguły nakazujące ustalony sposób postępowania z problematycznymi elementami i konstrukcjami języka. W efekcie umożliwia uniknięcie znaczącej większości potencjalnych defektów i zauważalną poprawę jakości programu.

być zarówno 0x40000000, jak i 0xC0000000
Znaczna część błędów w kodzie źródłowym pisanym w językach C oraz C++ powodowana jest przez niezdefiniowane lub zależne od implementacji zachowanie pewnych fragmentów programu. Typowy przykład tego typu sytuacji pokazano na rysunku 1. Standard C nie definiuje jasno zachowania kompilatora w przypadku przesunięcia bitowego w prawo. Najstarsze bity mogą być zatem uzupełnione wartością 0 lub 1, zależnie od typu kompilatora. Skutkuje to możliwością otrzymania różnych danych wyjściowych przy korzystaniu z tego samego kodu źródłowego skompilowanego przy użyciu odmiennych narzędzi.
Równie nieprzewidywalne jest zachowanie funkcji przedstawionej na ryDice() wielokrotnie wywołuje funkcję rollDice(), która odczytuje kolejną wartość z bufora cyklicznego. Jeśli w buforze umieszczone zostaną kolejno liczby 1, 2, 3, 4, to oczekiwanym rezultatem działania funkcji powinna być wartość 1234. Nie ma jednak żadnej gwarancji wywołania kolejnych odwołań do rollDice() właśnie w tym porządku. W zależności od zachowania kompilatora, końcowy wynik może być całkiem odmienny, wynosząc np. 3412.

Na programistów korzystających z C oraz C++ czeka wiele innych pułapek tego typu: korzystanie z wyrażeń typu goto lub malloc, operacje wykonywane jednocześnie na zmiennych typu signed oraz unsigned i związana z tym konwersja typów, korzystanie ze wskaźników czy niska czytelność kodu źródłowego. Każda z wymienionych przyczyn może w rezultacie prowadzić do powstania błędu w programie.
Implementacja standardów wytwarzania oprogramowania jest działaniem prewencyjnym, pozwalającym ograniczyć ryzyko wystąpienia błędów w kodzie. Pozwala zapobiegać korzystaniu z ryzykownych wyrażeń, a przynajmniej wymusić używanie ich w kontrolowany i staranny sposób. Wymusza uporządkowanie, ujednolicenie oraz udokumentowanie kodu źródłowego. Nawet określenie pozornie mało istotnych detali dotyczących formatowania tekstu, jak np. sposobu wykorzystania wcięć w kodzie, czy też umieszczania w nim nawiasów, prowadzi do znaczącej poprawy jego czytelności i w efekcie upraszcza i usprawnia późniejszą ręczną inspekcję.
Standard MISRA
Prawdopodobnie najbardziej rozpowszechnionym zestawem reguł i wytycznych dotyczących programowania w językach C oraz C++ jest standard MISRA (Motor Industry Soft ware Reliability Association). Jego pierwsza wersja opublikowana została w 1998 roku w dokumencie pod nazwą Guidelines For the Use of the C Language In Critical Systems. Druga wersja zaleceń opublikowana została w 2004 roku, zaś w 2008 roku ukazała się publikacja standardu dla języka C++.
Projekt ten powstał przede wszystkim z myślą o wytwarzaniu oprogramowania na potrzeby przemysłu motoryzacyjnego, obecnie jest jednak powszechnie stosowany we wszystkich systemach, które wymagają wysokiego poziomu niezawodności – m.in. w branży lotniczej, medycznej, kolejowej, telekomunikacyjnej czy militarnej.
Część zasad standardu MISRA została zaimplementowana do większości popularnych kompilatorów C/C++. Dokumentacja standardu zawiera uzasadnienie wprowadzenia każdej z reguł, razem ze szczegółami opisującymi wszelkiego rodzaju potencjalne wyjątki i odstępstwa od celowości jej stosowania. Dla większości przypadków wymienione są również przykłady błędnego, nieokreślonego lub zależnego od implementacji zachowania aplikacji będącego efektem niestosowania się do danej zasady. Przykładowy wpis dla jednej z reguł przedstawiono na rysunku 3.
Większość wytycznych standardu MISRA ma etykietę Decidable, co oznacza, że narzędzie weryfikujące jest w stanie jednoznacznie ocenić, czy dany fragment kodu stanowi naruszenie reguły, czy też nie. W zbiorze zasad znajdują się jednak również wskazówki zakwalifikowane jako Undecidable, co oznacza, że nie zawsze istnieje możliwość jednoznacznego określenia naruszenia danej reguły, prowadząc do ryzyka powstania fałszywych alarmów.


Przykładowo, niezainicjowana zmienna przekazana do funkcji systemowej może być zarejestrowana jako błąd, nawet jeśli w tej funkcji odbywa się inicjalizacja zmiennej. Wynika to z faktu, że narzędzie do statycznej analizy kodu może nie mieć dostępu do kodu funkcji systemowych. W efekcie prowadzić to może do uzyskania nieprawidłowych wyników analizy kodu – zarówno fałszywie dodatnich, jak i fałszywie ujemnych.
W 2016 roku do standardu MISRA dodano 14 nowych reguł mających na celu poprawę poziomu bezpieczeństwa oprogramowania. Jedną z tych zasad pokazano na rysunku 4. Reguła 4.14 pomaga rozwiązać problemy związane z przekazywaniem niepoprawnych lub niezainicjowanych wartości do funkcji.
Tradycyjnie stosowanie rygorystycznych standardów tworzenia oprogramowania kojarzone było przede wszystkim z systemami i infrastrukturą o krytycznym znaczeniu, gdzie potencjalny błąd mógł doprowadzić do katastrofalnych skutków, zagrażających zdrowiu i życiu użytkowników. Standard MISRA znajdował więc zastosowanie w środkach transportu czy urządzeniach medycznych. Współczesna złożoność kodu systemów mikroprocesorowych, szczególne znaczenie kwestii bezpieczeństwa (zwłaszcza w aplikacjach IoT połączonych z Internetem), a także ogromna konkurencja na rynku generująca presję tworzenia i dostarczania użytkownikom wysokiej jakości produktu powodują, że implementacja standardów programowania staje się rozsądnym wyborem dla całej branży embedded. Wymaga to przede wszystkim zaopatrzenia się w odpowiednie narzędzia weryfikujące, zdolne do skutecznego badania zgodności kodu źródłowego z wytycznymi standardu. W zależności od potrzeb projektu, zdecydować się można na przyjęcie całości standardu lub jedynie jego wybranych reguł, odstępując od innych ze względu na specyfikę konstruowanego systemu. W dodatku każdy projektant i programista systemów wbudowanych może bez wątpienia wynieść wiele korzyści z lektury dokumentacji standardu, poznając dzięki temu potencjalne słabości i pułapki języka programowania, a także ucząc się sposobów bezpiecznego ich obchodzenia.
Testowanie programu
Narzędzia do weryfikacji i statycznej analizy kodu są w stanie rozwiązać wiele problemów i zapobiec propagacji znacznej większości błędów do końcowego kodu programu, jednak już istniejące w programie błędy zidentyfikować można jedynie za pomocą odpowiednio zaprojektowanych testów produktu. Zadaniem testów jest sprawdzenie, czy program zachowuje się zgodnie z wymaganiami, realizując dokładnie te zadania, do których został zaprojektowany. Sztuka unikania błędów podczas tworzenia oprogramowania składa się w zasadzie z dwóch podstawowych elementów – zaprojektowania właściwego urządzenia i dokonania tego we właściwy sposób.
Zaprojektowanie właściwego produktu oznacza przede wszystkim wytworzenie poprawnego i kompletnego zbioru wymagań, które urządzenie musi spełnić, ponadto zaś zapewnienie dwukierunkowej zależności i identyfikowalności pomiędzy wymaganiami a kodem źródłowym. Dzięki temu możliwe jest znalezienie funkcji/fragmentów kodu implementujących każde z wymagań, a także działanie odwrotne, czyli sprawdzenie zbioru wymagań, które implementuje każda z funkcji. Uzyskanie takiego efektu pozwala na łatwą identyfikację nadmiarowych fragmentów kodu (nieimplementujących żadnej wymaganej funkcjonalności) oraz niezaimplementowanych wymagań – obie tego typu sytuacje uznaje się za błąd programu, który powinien zostać naprawiony. Projektowanie produktu we właściwy sposób oznacza upewnienie się, że kod źródłowy urządzenia spełnia wszystkie postawione wymagania – w tym celu wykorzystuje się testy oparte na odpowiednio przygotowanych przypadkach testowych.
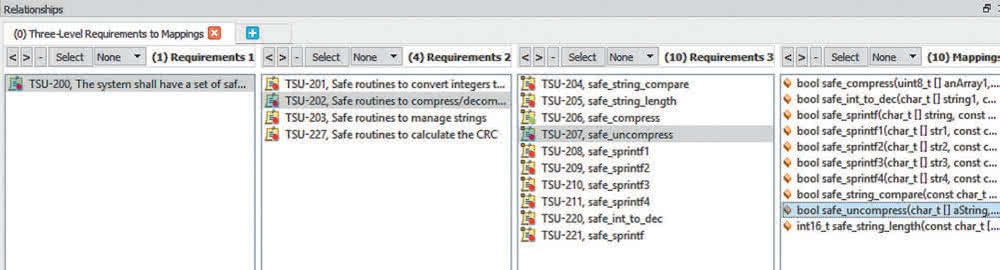
Przykład dwukierunkowej identyfikowalności pomiędzy programem a wymaganiami przedstawiono na rysunku 5. Wybranie pojedynczej funkcji pozwala prześledzić wszystkie dotyczące jej wymagania – od nisko- do wysokopoziomowych. To samo osiągnąć można też w odwrotnym kierunku – dla każdego z wymagań prześledzić można wszystkie implementujące je funkcje oraz wymagania niższych poziomów. Tego typu funkcjonalności, polegające na możliwości definiowania oraz budowania drzewek zależności pomiędzy kodem a wymaganiami, udostępnianie są w zasadzie przez wszystkie narzędzia służące do zarządzania projektami programistycznymi. Umiejętne wykorzystanie tych funkcji pozwala na detekcję błędów programu na wczesnym etapie projektu, już podczas fazy planowania.
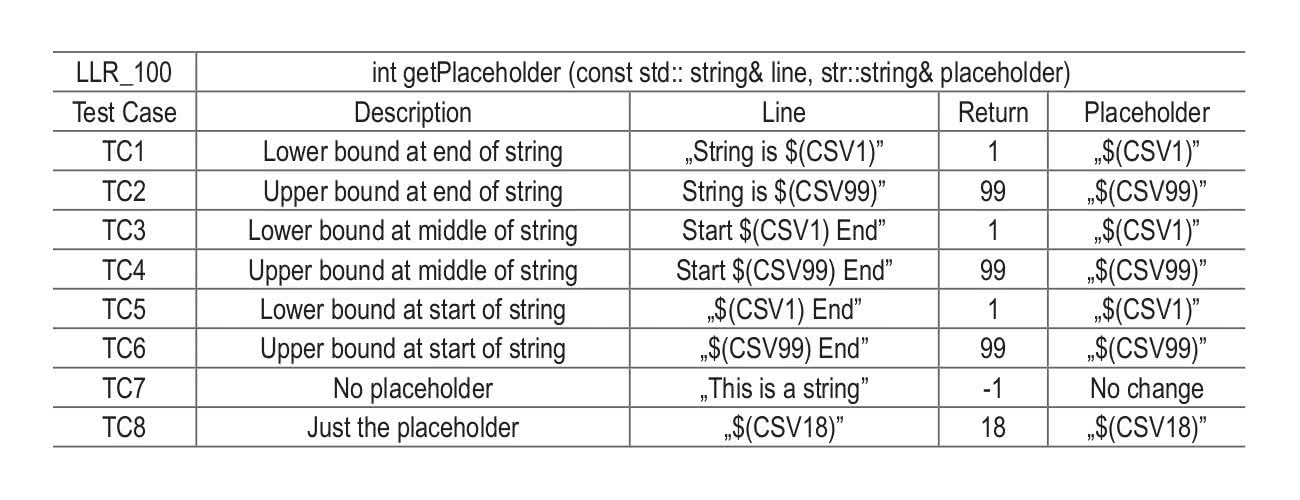
Dokładne przetestowanie kodu wymaga dogłębnej znajomości zasad i wymagań działania programu, możliwości wystąpienia potencjalnych sytuacji szczególnych oraz zależności pomiędzy elementami systemu. Informacje takie powinny być zawarte w wymaganiach niskiego poziomu, opisujących zamierzenia i ograniczenia dotyczące działania każdej z funkcji. Przykład takiego wpisu przedstawiono na rysunku 6 – zawiera informację na temat pożądanego działania funkcji, przyjmowanych wartości wejściowych oraz zwracanych wartości wyjściowych.

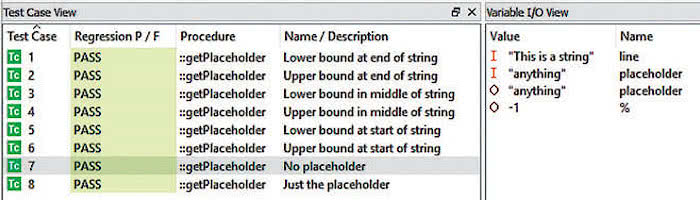
Poszczególne przypadki testowe opracowywane są właśnie na podstawie wymagań niskopoziomowych, tak jak pokazano na rysunku 7. Z użyciem dowolnego środowiska testującego, możliwe jest uruchomienie przygotowanych testów w sprawdzanym programie wraz z wizualizacją uzyskanych wyników. Właściwy dobór testów pozwala na całkowite pokrycie kodu programu i w praktyce identyfikację niemal wszystkich występujących w nim błędów. Narzędzia do testowania pozwalają na zmierzenie pokrycia kodu źródłowego testami – dąży się do uzyskania wartości 100%, choć nie jest to oczywiście gwarancja skutecznej detekcji wszystkich błędów.
Podsumowanie
Nie ma wątpliwości, że wraz z rozwojem możliwości mikroprocesorów wzrasta złożoność przeznaczonego dla nich oprogramowania, to zaś przekłada się na większe prawdopodobieństwo powstania błędów i trudniejszą ich lokalizację. Usprawnienie procesu tworzenia oprogramowania w oparciu o sprawdzone wzorce i techniki jest jedną z recept na poprawę jakości dostarczanego kodu oraz spełnienie rosnących oczekiwań użytkowników.
Tworzenie oprogramowania według reguł zdefiniowanych w określonych dokumentach standaryzacyjnych, takich jak MISRA, znacząco zmniejsza ryzyko powstania błędu, zwiększa też czytelność i przejrzystość kodu źródłowego. Standard ten, początkowo opracowany z myślą o systemach o krytycznym znaczeniu dla bezpieczeństwa, może być z powodzeniem wdrożony do każdego projektu, częściowo lub w całości. Lektura i znajomość reguł zwartych w dokumentacji MISRA niewątpliwie przyniesie wiele korzyści każdemu programiście embedded, zwiększając jego świadomość na temat zagrożeń związanych ze stosowaniem języka C/ C++ i zalecanych sposobów ich minimalizacji.
Precyzyjne zdefiniowanie wymagań oraz wykreślenie dwukierunkowej zależności pomiędzy nimi i tworzonym kodem pozwala uzyskać wysoki poziom kontroli nad projektem, identyfikować brakujące oraz nadmiarowe elementy systemu, a także w przejrzysty i szybki sposób przygotować zestaw przypadków testowych, sprawdzających poprawność pracy opracowanego oprogramowania. Eliminacja błędów na wczesnym etapie projektowania systemu pozwala przynieść oszczędności czasowe, finansowe, a także uchronić użytkowników przed potencjalnymi zagrożeniami związanymi z błędnym i niebezpiecznym działaniem produktu.
Damian Tomaszewski








