
Trenowanie algorytmów sztucznej inteligencji na dużych zbiorach danych tradycyjnie odbywa się w chmurze, w oparciu o zasoby przystosowanych do tego celu serwerów. Również wytrenowane modele są tam hostowane. Wraz z rosnącym zapotrzebowaniem na funkcje AI w różnego rodzaju urządzeniach przeniesienie modeli z chmury bezpośrednio na nie przynosi jednak liczne korzyści. Pozwala przede wszystkim na skrócenie czasu reakcji oraz ograniczenie ilości danych, które są udostępniane w chmurze. To zmniejsza wymagania w zakresie przepustowości sieci. Oprócz tego funkcje AI są dostępne nawet w przypadku przerwania połączenia z chmurą. Minimalizacja ilości danych wysyłanych do chmury zapewnia ich prywatność. Ważne jest również to, że przeniesienie obciążenia na lokalne urządzenia radykalnie zmniejsza zużycie energii w centrach danych.
Upowszechnianie się przetwarzania brzegowego wiąże się jednak z wyzwaniami w projektowaniu systemów wbudowanych. Przede wszystkim algorytmy sztucznej inteligencji są bardzo obciążające obliczeniowo, z czego wynika bardzo duże zużycie energii. Oprócz tego mikrokontrolery ogólnego przeznaczenia mają ograniczoną pamięć oraz moc obliczeniową. To skutkuje opóźnieniami, które wpływają na pogorszenie wydajności oraz wygody użytkowania aplikacji AI, w szczególności tych działających w czasie rzeczywistym.
Czym są NPU?
Aby sprostać wymaganiom algorytmów sztucznej inteligencji, potrzebne są jednostki obliczeniowe nowego typu, alternatywne w stosunku do tych tradycyjnych zaprojektowanych pod kątem obliczeń sekwencyjnych i w związku z tym nieprzystosowanych do uruchamiania modeli AI tak sprawnie, jak potrzebują tego ich aplikacje. Wymagane są architektury, które umożliwią szybkie i wydajne działanie algorytmów AI, pomimo typowych ograniczeń systemów wbudowanych w zakresie dostępnej pamięci, mocy obliczeniowej, dopuszczalnego zużycia energii i maksymalnego rozmiaru. Warunki te spełniają jednostki przetwarzania neuronowego NPU, czyli akcelerometry AI, które realizuje się w architekturze przetwarzania równoległego sterowanego danymi (data-driven parallel computing), optymalizując je na poziomie sprzętowym pod kątem obciążeń typowych dla operacji matematycznych będących podstawą działania sieci neuronowych, przede wszystkim mnożenia macierzy.
NPU są przeważnie komponentem heterogenicznych architektur obliczeniowych, łączących wiele typów procesorów, na przykład CPU i GPU. W centrach danych korzysta się z akceleratorów tego typu podłączanych bezpośrednio do serwera. W elektronice użytkowej, szczególnie w urządzeniach mobilnych, NPU są integrowane w ramach układów SoC jako wyspecjalizowane koprocesory. Dostępne są również mikrokontrolery wyposażone w jednostki przetwarzania neuronowego.
Integracja NPU znacząco rozszerza ich możliwości, pozwalając na obsługę złożonych zadań AI, wcześniej będących poza ich zasięgiem. Do tej pory na mikrokontrolerach implementowano przede wszystkim algorytmy sztucznej inteligencji do obsługi prostszych operacji, jak analiza obrazów o niskiej rozdzielczości, przetwarzanie wideo o małej liczbie klatek na sekundę czy analiza szeregów czasowych. Dzięki NPU do tej listy dopisać można przetwarzanie języka naturalnego, klasyfikację obiektów czy estymację położenia.
Jednostki przetwarzania neuronowego mają kilka cech, które je wyróżniają. Taką jest obsługa przetwarzania równoległego.
Przetwarzanie równoległe
Przetwarzanie równoległe polega na podziale skomplikowanego problemu obliczeniowego na wiele mniejszych zadań wykonywanych współbieżnie przez kilka jednostek obliczeniowych. Zależnie od architektury systemu mogą one korzystać z pamięci współdzielonej albo komunikować się między sobą w sieci, korzystając z pamięci rozproszonej. Uzyskane przez nie wyniki częściowe są następnie łączone w całość, co pozwala uzyskać spójne rozwiązanie. Przetwarzanie równoległe to alternatywa dla podejścia sekwencyjnego, w którym instrukcje są wykonywane kolejno, jedna po drugiej, przez pojedynczą jednostkę obliczeniową.
Zanim przetwarzanie równoległe stało się standardem, rozwiązywanie problemów obliczeniowych odbywało się głównie sekwencyjnie, w procesorach jednordzeniowych. Praktycznie wiązało się to z ograniczoną szybkością działania aplikacji i wolniejszą reakcją systemu na polecenia użytkownika. Odczuwali to m.in. korzystający z urządzeń mobilnych. Przykładowo w iPhone’ach dopiero wraz z wprowadzeniem procesorów wielordzeniowych, począwszy od modelu 4S z 2011 roku, użytkownicy zaczęli realnie doświadczać systematycznej poprawy płynności ich obsługi.

Podział zadań
Obecnie, w miarę jak przybywa danych do analizy, w tym do trenowania modeli sztucznej inteligencji, a problemy obliczeniowe stają się coraz bardziej złożone, nie można już sobie pozwolić na wąskie gardła spowodowane ograniczeniem się do wykonywania tylko jednego ciągu obliczeń na raz na pojedynczym procesorze. W rezultacie przetwarzanie równoległe jest podstawą wielu technologii napędzających współczesny świat, jak blockchain czy Internet Rzeczy.
Przykładowo, w trenowaniu modeli AI, zadaniu wymagającym dużych zasobów pamięci oraz mocy obliczeniowej, paralelizację obliczeń i dzięki temu efektywne rozłożenie obciążeń zapewnić może współpraca CPU z GPU. W takim przypadku ten pierwszy zazwyczaj odpowiada za ładowanie oraz wstępne przetwarzanie danych, koordynację pętli treningowej oraz zarządzanie operacjami wejścia/wyjścia, z kolei GPU, zoptymalizowany pod kątem przetwarzania równoległego, realizuje zadania wymagające operacji na macierzach i w propagacji wstecznej w sieciach neuronowych. By uzyskać jak największą wydajność, konieczna jest synchronizacja CPU i GPU. Dzięki temu zapobiega się przestojom, które wynikają z oczekiwania jednej jednostki na zakończenie zadania przez tę drugą. Dodatkowo, w przypadku większych modeli i zestawów danych wykorzystanie wielu GPU pozwala znacząco zwiększyć wydajność.
Tablice systoliczne
ednostki przetwarzania neuronowego NPU są projektowane pod kątem wykonywania bardzo dużej liczby operacji jednocześnie. W tym celu stosuje się w nich specjalne rozwiązania sprzętowe. Takim jest organizacja wielu identycznych, bazowych jednostek obliczeniowych w postaci modułów MAC (Multiply–Accumulate), które w jednym cyklu zegara wykonują operację mnożenia i dodawania, w formie tablicy systolicznej (skurczowej). Nazwę struktura, na której opiera się wiele realizacji NPU, zawdzięcza podobieństwu regularności, z jaką w obrębie niej wykonywane są obliczenia względem przepływu danych, do pracy serca, którego rytm wyznaczają kolejne skurcze. Najlepiej wyjaśnić to na przykładzie.
Na rysunku 1a przedstawiono dwuwymiarową tablicę systoliczną zbudowaną z modułów MAC. Może mieć ona różną albo równą liczbę kolumn, a dane między sąsiednimi jednostkami obliczeniowymi przesyłane są w poziomie albo pionowo. Jako przykład wyjaśniający przebieg obliczeń w tablicy systolicznej posłuży operacja splotu. Dla uproszczenia przyjęto stałe wagi, a wartości wejściowe i sumy częściowe są przesyłane w poziomie i w pionie. Wagi W i G są zapisane w jednostkach obliczeniowych, a dane wejściowe F są wprowadzane do tablicy sekwencyjne, z opóźnieniem o jeden cykl zegara w każdym wierszu.

W pierwszym cyklu zegara (rys. 1b) dane wejściowe F00 trafiają do modułu MAC z wagą W00. Wynik jednostkowy Y00 jest pierwszą sumą częściową. W drugim cyklu zegara (rys. 1c) trafia ona do modułu MAC z wagą W01, gdzie zostaje zsumowana z wynikiem mnożenia danych wejściowych F01 z wagą W01. Jednocześnie próbka F01 trafia do modułu z wagą W00, czego wynikiem jest suma częściowa Y01, a próbka F00 jest przesuwana w prawo, do modułu MAC z wagą G00, co pozwala uzyskać kolejną sumę częściową Y10. Zasada jest więc prosta: dane wejściowe są przesuwane w prawo, by wygenerować sumy częściowe, które przesuwają się w dół i kumulują się z wynikami bieżącymi z modułów MAC. Pierwszy wynik operacji splotu uzyskiwany jest pod koniec ósmego cyklu zegara (rys. 1d), zaś po dziewiątym w każdym kolejnym kroku uzyskiwane są po dwa wyniki (rys. 1e).

Czym jest funkcja aktywacji?
W przeciwieństwie do tradycyjnych procesorów, NPU nie są przeznaczone do wysoce dokładnych obliczeń. Dlatego jednostki przetwarzania neuronowego zwykle wykonują operacje arytmetyczne ze zmniejszoną precyzją, na przykład 8-bitową, a nawet niższą. To zmniejsza złożoność obliczeń, poprawiając ich wydajność i szybkość i równocześnie ograniczając zużycie energii. Wynika to stąd, że zazwyczaj modele AI nie wymagają bardzo dokładnych obliczeń, aby uzyskać poprawne wyniki, inaczej niż typowe zadania realizowane przez CPU czy GPU, które w związku z tym opierają się na arytmetyce zmiennoprzecinkowej o wysokiej precyzji. Kolejną cechą charakterystyczną NPU jest wbudowana pamięć o dużej przepustowości, dzięki której wydajnie obsługują złożone modele AI i duże zbiory danych, bez wąskich gardeł na etapie transmisji danych.
Oprócz MAC, częścią NPU są standardowo także inne, wyspecjalizowane bloki. Jednym z nich jest moduł funkcji aktywacji, który odpowiada za realizowanie transformacji nieliniowych w sieciach neuronowych.
Funkcja aktywacji to matematyczna reguła, która na podstawie ważonej sumy sygnałów na wejściu neuronu wyznacza wartość jego wyjścia i decyduje, w jakim stopniu sygnał zostanie przekazany do kolejnej warstwy. Pełni ona kluczową funkcję w procesie uczenia sieci neuronowych, gdyż umożliwia modelowanie nieliniowych zależności. To pozwala modelom sztucznej inteligencji na rozpoznanie skomplikowanych związków pomiędzy danymi, wykraczających poza te proste, liniowe. Bez tego sieci neuronowe nie byłyby użyteczne na przykład w rozpoznawaniu obrazów ani przetwarzaniu języka naturalnego. W NPU implementacja funkcji aktywacji zwykle opiera się na aproksymacji z wykorzystaniem parametrów wyższego rzędu, co pozwala efektywnie realizować różne ich typy, takie jak ReLU, Sigmoid, Tanh, przy zachowaniu równowagi między dokładnością a wydajnością obliczeniową.

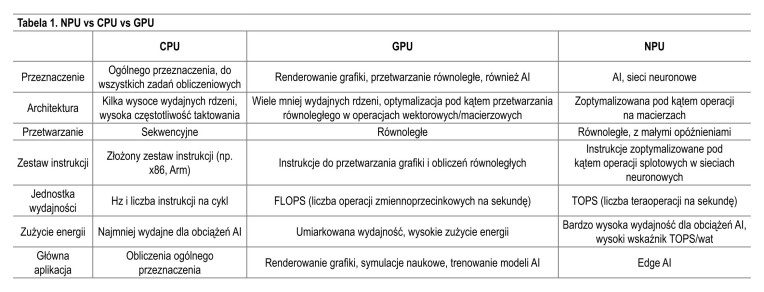
NPU vs CPU vs GPU
Kolejnym blokiem funkcyjnym w NPU jest moduł manipulacji danymi 2D, zoptymalizowany pod kątem operacji planarnych na danych, takich jak downsampling i planarna replikacja danych. Tego typu działania odgrywają kluczową rolę w zadaniach przetwarzania obrazów i wizji komputerowej. Częścią NPU są również moduły kompresji i dekompresji danych.
Jednostki przetwarzania neuronowego nie są projektowane jako zamienniki dla procesorów CPU ani GPU. Mimo to często się je z nimi porównuje, dlatego w tabeli przedstawiamy zestawienie ich najważniejszych cech.
Monika Jaworowska









