
Czasy szybkiego postępu w zakresie zwiększania częstotliwości taktowania procesorów oraz mikroprocesorów można już niestety uznać za minione – ograniczenia związane z przesyłaniem oraz przetwarzaniem sygnałów wysokiej częstotliwości i trudności w redukcji rozmiarów tranzystora wydają się skutecznie hamować dalszy dynamiczny wzrost tego parametru. Trudno również uzyskać znaczący wzrost wydajności za pomocą zabiegów programowych – współczesne kompilatory oraz narzędzia do optymalizacji i przeglądu kodu są wysoce precyzyjne oraz skuteczne, nie ma zatem zbyt wielu możliwości znaczącej korekty efektów ich pracy, szczególnie poprzez ręczne zabiegi programisty. Wszystko to powoduje, że współcześnie najłatwiejszym sposobem poprawy wydajności i mocy obliczeniowej systemu mikroprocesorowego jest zrównoleglenie jego pracy, czyli zastosowanie architektury wielordzeniowej.
Programowanie równoległe – podstawowe pojęcia
Implementacja mechanizmów przetwarzania równoległego często wymaga przemodelowania całości działania systemu, przede wszystkim poprzez podział jego pracy na mniejsze zadania, możliwe do równoległej realizacji. Niestety nie każdy rodzaj problemu pozwala się łatwo sprowadzić do postaci skończonej liczby równolegle wykonywanych operacji, przez co efektywność wprowadzenia architektury wielordzeniowej różni się znacząco w zależności od charakteru danego systemu.
W codziennym życiu za przykład zadania trudnego do zrównoleglenia posłużyć może kopanie studni. Wielu ludzi może pomóc kopaczowi przez odgarnianie już wydobytego materiału i wykonywanie innych prac pomocniczych, jednak właściwe zadanie kopania może być przypisane jedynie jednej osobie na raz. Umieszczenie większej liczby kopaczy w niewielkim otworze nie przyspieszy wykonania tej pracy. Co więcej, mogą oni sobie jedynie nawzajem przeszkadzać, co w efekcie spowolni tempo.

Istnieje jednak wiele problemów, które świetnie nadają się do zrównoleglenia, ponieważ ich rozwiązanie składa się z pewnej liczby równolegle wykonywanych mniej lub bardziej niezależnych operacji. W świecie inżynierskim do zagadnień tego typu zaliczyć można większość procesów produkcyjnych, a nawet biologicznych. Poprzez analogię do problemu kopania studni, za przykład procesu nadającego się do zrównoleglenia posłużyć może kopanie rowu. Wielu kopaczy może pracować jednocześnie obok siebie, nie przeszkadzając sobie wzajemnie, zatem N pracujących jednocześnie osób wykona to zadanie N razy szybciej niż jeden kopacz.

Jednoczesny wysiłek wielu kopaczy to przykład modelu pracy równoległej określanego jako MIMD (Multiple Instruction, Multiple Data). W modelu tym przetwarzanie równoległe zachodzi zarówno na poziomie danych, jak i instrukcji. Każdy z procesorów pracuje zatem niezależnie oraz asynchronicznie, dzięki czemu mogą one w tym samym momencie wykonywać różne instrukcje na odmiennych zbiorach danych.
Alternatywny model, określany jako SIMD (Single Instruction, Multiple Data), mógłby zostać zobrazowany jako pojedynczy kopacz posługujący się narzędziem umożliwiającym jednoczesną pracę wielu łopat. Układ typu SIMD potrafijednocześnie przetwarzać wiele strumieni danych oraz tylko jeden strumień rozkazów. Architektura taka charakterystyczna jest dla procesorów wektorowych, zdolnych do jednoczesnych operacji na większych zbiorach danych tworzących wektor. Układy takie znajdują zastosowanie w wielu specyficznych przypadkach użycia, związanych między innymi z przetwarzaniem informacji graficznych oraz wykonywaniem pewnych rodzajów obliczeń naukowo-technicznych. Rozkazy typu SIMD znaleźć można również w popularnych architekturach procesorów komputerów domowych, jak np. x86.
Prawo Amhdala
Możliwości zwiększenia efektywności rozwiązania problemu za pomocą zrównoleglenia obliczeń opisywane są przez tzw. prawo Amhdala. Zgodnie z tym wywodem każdy program zredukować można do dwóch składników – części równoległej, możliwej to przetworzenia współbieżnego oraz części sekwencyjnej, niemożliwej do takiego przetworzenia. Zatem zwiększenie szybkości wykonywania programu przy użyciu wielu procesorów w obliczeniach równoległych ograniczane jest przez czas potrzebny na wykonanie części sekwencyjnej. Przykładowo, jeśli całość programu wymaga 20 godzin obliczeń przeprowadzonych na procesorze jednordzeniowych, zaś z tego 1 godzina nie może zostać przetworzona przez obliczenia równoległe, to minimalny czas wykonania programu nigdy nie będzie krótszy niż 1 godzina, bez względu na liczbę wykorzystanych do rozwiązania tego problemu procesorów. Dla takiego systemu przyspieszenie wynikające z implementacji obliczeń równoległych nie może być zatem większe niż dwudziestokrotne.
Prawo to opisuje maksymalny przyrost efektywności, niemożliwy do uzyskania w rzeczywistych systemach. Nie uwzględnia bowiem strat czasu wynikających z opóźnień w dostępie do wspólnych danych, nierównego obciążenia wszystkich rdzeni oraz niezbędnej komunikacji pomiędzy rdzeniami. W praktyce uzyskanie przyspieszenie będzie zawsze mniejsze niż wynikające z prawa Amhdala. Z reguły im większa jest liczba wykorzystywanych rdzeni, tym większe straty związane z synchronizacją i koordynacją ich pracy, tym mniejsza zatem zgodność rzeczywistych osiągów systemu z teoretycznymi obliczeniami opartymi na prawie Ahmdala.
Rodzaje systemów wielordzeniowych
Procesory wielordzeniowe mogą charakteryzować się różnymi właściwościami, w zależności od ich konstrukcji. Szczególnie duże znaczenie ma rodzaj rdzeni zaimplementowanych w układzie oraz sposób dystrybucji zasobów pomiędzy nimi.
Procesory homogeniczne to układy składające się ze skończonej liczby takich samych rdzeni – w zasadzie każdy z rdzeni jest kopią wszystkich pozostałych. Każdy z nich może pracować autonomicznie, zaś z innymi komunikuje się i synchronizuje poprzez różnego typu dedykowane mechanizmy, zależne od implementacji – może to być m.in. wspólna przestrzeń pamięciowa, specjalistyczne rejestry, flagi lub wewnętrzny protokół komunikacyjny. Każdy z rdzeni ma własne rejestry oraz jednostki funkcjonalne, zazwyczaj wyposażony jest też we własną pamięć cache oraz operacyjną. Homogeniczność procesora polega jednak na wykorzystaniu do jego konstrukcji rdzeni tego samego typu. Architektura taka jest bardzo elastyczna i świetnie sprawdza się w aplikacjach ogólnego przeznaczenia, urządzeniach mobilnych oraz komputerach domowych. Identyczne możliwości obliczeniowe wszystkich rdzeni ułatwiają systemowi operacyjnemu właściwy rozdział zadań i umożliwiają losowy przydział wątków do określonych rdzeni. Procesory homogeniczne są zatem dominującym rodzajem układów wielordzeniowych w systemach komputerowych ogólnego przeznaczenia, pracujących pod kontrolą systemu operacyjnego.
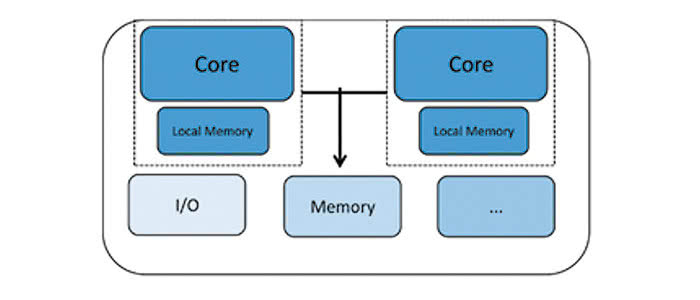
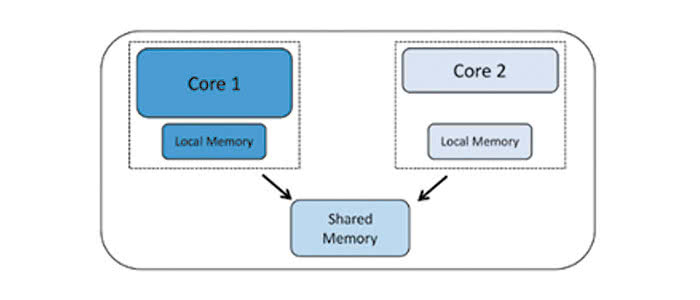
W przeciwieństwie do nich, procesory heterogeniczne składają się z rdzeni o różnej architekturze. Rdzenie te mogą mieć bardzo różniące się od siebie charakterystyki, dzięki czemu nadają się do wykonywania zadań o odmiennym charakterze. Rozdział pracy pomiędzy rdzeniami procesora heterogenicznego jest bardzo istotnym zagadnieniem, zależnym od przeznaczenia i roli systemu. Przykładem tego typu układu może być moduł do komunikacji w technologii Bluetooth, w którym jeden rdzeń przeznaczony będzie do zarządzania stosem protokołów standardu komunikacyjnego, czyli zadaniem wymagającym dużej mocy obliczeniowej, drugi zaś zajmie się obsługą interfejsu użytkownika, pozostając przez większość czasu w trybie bardzo niskiego zużycia energii elektrycznej. Typowym przypadkiem użycia procesora heterogenicznego jest właśnie konieczność jednoczesnej obsługi dwóch lub więcej zadań, przy czym tylko część z nich wymaga dużej mocy obliczeniowej oraz precyzji charakterystycznej dla systemów czasu rzeczywistego. Pozostałe mogą być z reguły obsłużone przez słabszą obliczeniowo jednostkę, charakteryzującą się za to lepszą efektywnością energetyczną. Z tego wynika najczęściej spotykana heterogeniczna konstrukcja procesora, czyli połączenie rdzenia o wysokiej wydajności z rdzeniem dedykowanym do pracy w trybie niskiego zużycia energii. Wydajny energetycznie rdzeń prowadzi zazwyczaj ciągły monitoring otoczenia i w razie potrzeby wybudza szybki rdzeń na czas wykonania niezbędnych obliczeń oraz operacji.
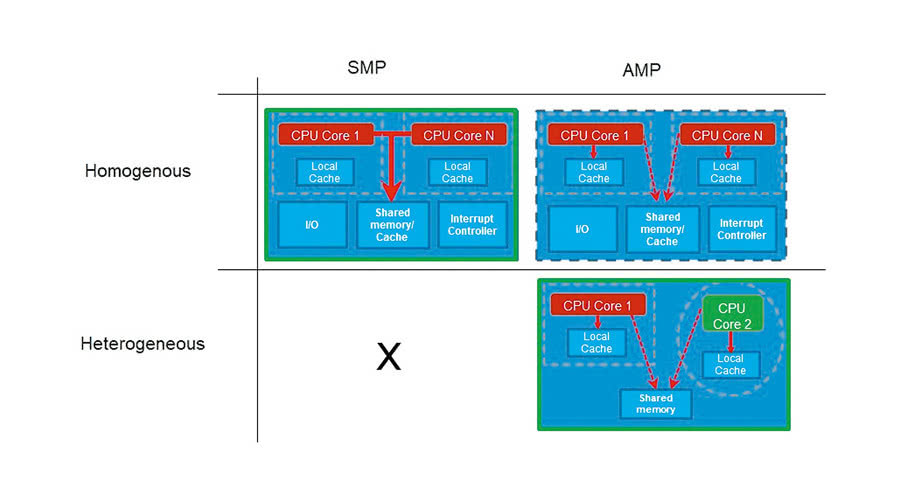
Wieloprocesorowość symetryczna
Systemy wieloprocesorowe klasyfikować można również ze względu na sposób podziału pracy pomiędzy rdzeniami. Jeśli zadania mogą być przydzielane jednakowo dla wszystkich rdzeni a dodatkowo współdzielą one wszystkie zasoby systemu, takie jak pamięć oraz układy wejścia/wyjścia, mamy do czynienia z architekturą komputerową określaną jako wieloprocesorowość symetryczna (SMP, Symmetric MultiProcessing). Architektura taka możliwa jest do realizacja jedynie w układach homogenicznych.
Wieloprocesorowość asymetryczna
W architekturze asymetrycznej (AMP, Asymmetric MultiProcessing) nie wszystkie rdzenie traktowane są jednakowo. Przykładowo, do wybranych z nich mogą być na wyłączność przypisane określone zasoby, jak np. obsługa urządzeń wejścia/wyjścia. Architektura asymetryczna może zostać zbudowana zarówno w oparciu o układy homogeniczne, jak i heterogeniczne.
Korzyści z wykorzystania architektury wielordzeniowej
Historia ostatnich kilku lat pokazuje, że sformułowane w latach 60. XX wieku prawo Moore’a odnoszące się do okresowego podwajania dostępnej mocy obliczeniowej procesorów, stopniowo traci swoją aktualność. Częstotliwość taktowania nie podwaja się już, jak jeszcze kilkanaście lat temu, co 2–3 lata. W rzeczywistości wartość ta osiągnęła wielkości rzędu pojedynczych GHz już kilkanaście lat temu i od tej pory już raczej dalej znacząco nie wzrasta. Jedyną rozsądną drogą do dalszego wzrostu wydajności układów jest zatem wykorzystywanie mechanizmów przetwarzania równoległego, czyli konstruowanie procesorów wielordzeniowych.
Z drugiej jednak strony, podczas gdy częstotliwość taktowania układów osiągnęła okolice wartości granicznych, przynajmniej dla współczesnego poziomu technologicznego, rozmiar tranzystorów wciąż maleje. Wraz z redukcją wymiarów tranzystorów możliwe jest gęstsze ich upakowanie, dzięki czemu na tej samej powierzchni układu scalonego zmieścić można więcej elementów logicznych. Pozwala to na konstrukcję układów wielordzeniowych o stosunkowo małych rozmiarach, możliwych do wykorzystania w systemach embedded.
Systemy embedded mogą czerpać szczególne korzyści z układów heterogenicznych pracujących według modelu asymetrycznego. Jest to szczególnie użyteczne, jeśli urządzenie wykonuje dwa lub więcej zadań o różnych charakterystykach i wymaganiach obliczeniowych. Dobrą ilustracją takiego rozwiązania może być przytaczany już przykład modułu do komunikacji bezprzewodowej.

Wyzwania związane z wielordzeniowością
Architektura wieloprocesorowa niesie ze sobą ogromne możliwości, wymaga jednak od programisty pewnego wysiłku, zarówno w przypadku tworzenia całkowicie nowego oprogramowania, jak i migracji kodu opracowanego z myślą o systemie jednoprocesorowym. Oprogramowanie dedykowane do układów jednordzeniowych prawdopodobnie nie będzie w stanie efektywnie wykorzystać możliwości systemu wielordzeniowego bez wprowadzenia odpowiednich modyfikacji. Program taki musi zostać podzielony na możliwe do równoległej realizacji zadania, co nie jest architekturą powszechnie spotykaną w systemach embedded. Odpowiednia modyfikacja głównej pętli programu może nastręczać sporo trudności, szczególnie że zarówno zbyt mała, jak i zbyt duża liczba równolegle pracujących wątków może stanowić skuteczną barierę dla poprawy wydajności.
Jednym z podstawowych kłopotów jest konieczność korzystania z tych samych zasobów sprzętowych lub pamięciowych przez więcej niż jeden wątek. W celu utrzymania integralności danych oraz zapobiegania powstawaniu krytycznych błędów oprogramowania konieczne jest wprowadzenie odpowiednich mechanizmów dostępu do współdzielonych struktur. Metody te mogą opierać się o rozwiązania programowe (wzajemne wykluczenie, mechanizmy blokujące) lub programowo-sprzętowych (np. dedykowane rejestry semaforów). Nieoptymalnie zaprojektowane algorytmy współdzielenia zasobów mogą stanowić wąskie gardło oprogramowania i prowadzić do powstawania znaczących opóźnień, a w niektórych przypadkach nawet do całkowitego zablokowania aplikacji. Do najbardziej niebezpiecznych zjawisk należą zagłodzenie i zakleszczenie.
Zagłodzenie to sytuacja, w której jeden z wątków nie jest w stanie kontynuować zadania, ponieważ w nieskończoność czeka na dostęp do pewnego zasobu. Szczególnie łatwo sytuacja taka wystąpić może w przypadku równoległej pracy większej liczby wątków oraz wykorzystania algorytmów szeregowania opartych o priorytety w dostępie do zasobu. Jeśli wątki z wyższym priorytetem odpowiednio często próbować będą uzyskać akces do zasobu, wątek o najniższym priorytecie może nigdy go nie zdobyć.
Zakleszczenie polega na wzajemnym zablokowaniu dwóch lub więcej wątków. Zadania te czekają na zasoby uprzednio zajęte już przez siebie nawzajem, przez co nie są w stanie ich zwolnić. W przypadku braku mechanizmów rozwiązywania tej sytuacji system może przejść do stanu permanentnego zawieszenia, w zasadzie nie będąc w stanie wykonywać już dalej żadnego działania.
Kolejny problem z wydajnością wynikać może z nierównego podziału obciążenia pomiędzy rdzeniami. Jeśli jedne z zadań wykonywane są bardzo szybko, inne zaś zajmują sporo czasu, niektóre z rdzeni spędzać mogą znaczną część swojej pracy jedynie na czekaniu, marnując dostępną moc obliczeniową.
RTOS (Real-Time Operating System) może w pewnym stopniu pomóc w równomiernym rozłożeniu pracy pomiędzy rdzeniami, nie zastąpi jednak rozsądnego planowania oraz projektowania systemu. Szczególnie w architekturach symetrycznych (SMP) niemal konieczne jest zapewnienie podobnego obciążenia poszczególnych rdzeni. Podział pracy może zostać wykonany w oparciu o kryterium funkcji lub danych. W przypadku podziału w oparciu o dane, każdy z rdzeni wykonuje te same operacje, jednak korzysta z innego zbioru danych. W drugiej sytuacji rdzenie wykonują poszczególne kroki algorytmu, przekazując sobie otrzymane rezultaty. Dane wyjściowe jednej operacji stają się jednocześnie danymi wejściowymi kolejnej. Wybór optymalnej techniki podziału pracy zależy od charakterystyki systemu.
Debugowanie
Efektywne debugowanie pracy systemu wieloprocesorowego wymaga odpowiednich narzędzi. Wskazane jest, aby zintegrowane środowisko programistyczne (IDE) umożliwiało jednoczesny podgląd wszystkich rdzeni, a także niezależne uruchamianie i zatrzymywanie ich pracy. Pozwala to m.in. na pracę krokową jednego z rdzeni przy uruchomieniu lub zatrzymaniu pozostałych. Ustawianie pułapek w kodzie wykonywanym na różnych rdzeniach może być bardzo użyteczne do kontroli jednego z rdzeni w oparciu o stanie pozostałych.
Mechanizmy śledzenia pracy wielordzeniowej potrafią być dość trudne w implementacji. Jednoczesne zarządzanie strumieniem informacji z kilku źródłem oraz potencjalna konieczność poradzenia sobie ze zróżnicowanym charakterem danych mogących pochodzić z rdzeni różnych typów mogą okazać się skomplikowanym wyzwaniem.
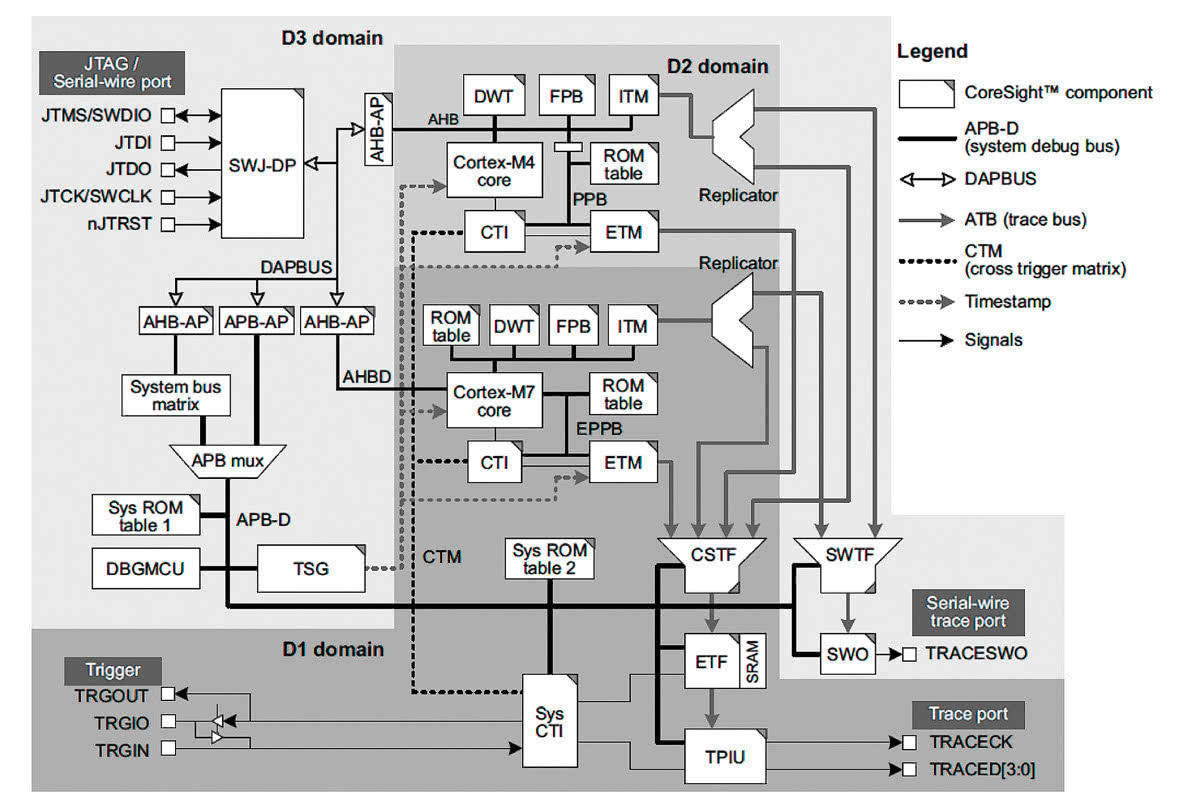
Na rysunku 6 przedstawiono przykład procesora o skomplikowanej budowie wewnętrznej, zawierającego zarówno elementy homogeniczne, jak i heterogeniczne. Składa się on z dwóch grup homogenicznych – podwójnego układu ARM Cortex-A57 oraz poczwórnego ARM Cortex-A53. Całość tworzy jednak układ heterogeniczny.
Opracowana przez ARM technologia CoreSight dostarcza protokołów i mechanizmów pozwalających na komunikację ze wszystkim zasobami debugowanego układu wielordzeniowego. Zadaniem debuggera pozostaje odpowiednie przetworzenie tej informacji i prezentacja jej użytkownikowi w czytelny sposób. W procesie tym główną rolę ogrywają następujące elementy architektury układu: CTI (Cross Trigger Interface) oraz CTM (Cross Trigger Matrix). Pozwalają na niezależne sterowanie pracą każdego rdzenia – jego wstrzymywanie oraz uruchamianie, na śledzenie wykonywanych instrukcji oraz podgląd zasobów. Do śledzenia wykorzystać można porty interfejsu szeregowego (SWD, Serial Wire Debug) lub równoległego (TPIU, Trace Port Interface Unit). Szczegółowy układ i sposób połączeń poszczególnych elementów przedstawiono na rysunku 7. Wyraźnie pokazuje on istotną rolę bloków CTI, połączonych ze sobą wzajemnie za pomocą CTM.
Współczesne zintegrowane środowiska programistyczne bardzo często wspierają programowanie oraz debugowanie systemów wielordzeniowych. Funkcje takie znaleźć można w każdym z najpopularniejszych środowisk przeznaczonych do pracy z układami embedded. Zazwyczaj aplikacje te wspierają mechanizmy debugowania oraz śledzenia kodu wykonywanego na kilku rdzeniach. Zadaniem programisty jest nauczenie się poprawnego sposobu korzystania z tych możliwości – odpowiednia konfiguracja środowiska przebiega nieco odmiennie dla każdej z aplikacji.
Podsumowanie
Wielordzeniowość wydaje się współcześnie najlepszą i najłatwiejszą drogą do dalszej poprawy efektywności i mocy obliczeniowej procesorów i mikroprocesorów. Wiąże się ona jednak z pewnymi wyzwaniami, zapewne wciąż jeszcze obcymi dla sporej grupy programistów i konstruktorów, szczególnie w świecie embedded. Projektowanie i programowanie tego typu aplikacji wymaga innego podejścia oraz uwzględnienia większej liczby dodatkowych czynników, związanych chociażby z prawidłowym zaplanowaniem dostępu do współdzielonych zasobów. Wielordzeniowość i równoległość wykonywania operacji musi zostać również starannie uwzględniona na etapie testów. Testowanie aplikacji współbieżnych jest znacznie trudniejsze niż w przypadku ich sekwencyjnych odpowiedników. Możliwość wystąpienia zróżnicowanych zależności czasowych generuje w zasadzie nieskończony zbiór przypadków testowych, co w teorii uniemożliwia całkowite przetestowanie działania programu. Należy zatem rozsądnie dobrać warunki testowe oraz zapewnić mechanizmy detekcji oraz eliminacji potencjalnie niekorzystnych sekwencji działania.
Współczesne procesy wyposażone są w bogaty zestaw mechanizmów do debugowania, intensywnie wspierających pracę równoległą. Rolą programisty pozostaje jednak odpowiedni dobór i konfiguracja środowiska programistycznego, pozwalające na pełne wykorzystanie oferowanych możliwości kontroli i śledzenia wykonywania kodu.
Damian Tomaszewski









