
ML/AI przenosi przetwarzanie brzegowe na wyższy poziom, umożliwiając analizę danych i wnioskowanie u źródła. Pozwala to urządzeniu IoT, trzymając się tego przykładu, uczyć się i doskonalić na podstawie zebranego doświadczenia. Algorytmy tego typu analizują dane, szukając wzorców i podejmują decyzje, wykorzystując trzy sposoby uczenia się: nadzorowane, nienadzorowane i uczenie ze wzmocnieniem (reinforced learning).
Uczenie nadzorowane polega na wykorzystaniu przez algorytm przygotowanych wstępnie danych do treningu. Na przykład inteligentną kamerę bezpieczeństwa można trenować, wykorzystując zdjęcia i nagrania wideo osób stojących, idących, biegnących lub niosących przedmioty. Algorytmy nadzorowanego uczenia maszynowego obejmują regresję logistyczną i model Naive Bayes, z użyciem informacji zwrotnej do udoskonalania modelu, na podstawie których będą formułowane predykcje.
Uczenie bez nadzoru wykorzystuje nieoznaczone dane i algorytmy, takie jak klasteryzacja metodą K-Means i analiza głównych składowych do identyfikacji wzorców. Jest to idealne rozwiązanie do wykrywania anomalii. Na przykład w scenariuszu konserwacji predykcyjnej lub w aplikacji obrazowania medycznego algorytm sygnalizowałby nietypowe sytuacje lub aspekty obrazu w oparciu o model "typowości", który sam stworzył.
Uczenie ze wzmocnieniem to działanie metodą prób i błędów. Podobnie jak w trybie nadzorowanym, wymagane jest sprzężenie zwrotne. Ale zamiast po prostu poprawiać działanie algorytmu, sprzężenie zwrotne jest traktowane jako system nagród lub kar. Algorytmy tego typu to m.in. Monte Carlo i Q-learning.
W powyższych przykładach wspólnym elementem jest możliwość inteligentnej analizy obrazów, którą te techniki pozwalają zrealizować, np. w inteligentnej kamerze systemu bezpieczeństwa. Dzięki różnego typu czujnikom analiza obrazu może wykorzystywać składowe widma niewidoczne dla ludzkiego oka, takie jak podczerwień (używana w obrazowaniu termicznym) i ultrafiolet (UV).
Wyposażenie systemu embedded z przetwarzaniem brzegowym ML/AI w kolejne sensory dostarczające także inne dane, takie jak temperatura i wibracje, pozwala tworzyć rozwiązania odgrywające znaczącą rolę w konserwacji predykcyjnej maszyn przemysłowych.

Systemy wbudowane
Jak wspomniano, przed laty ML/AI wymagały znacznych zasobów obliczeniowych. Obecnie, w zależności od złożoności systemu, do implementacji ML i AI można wykorzystać typowe komponenty przeznaczone do pracy w aplikacjach embedded i IoT. Na przykład detekcję i klasyfikację obrazu można zaimplementować w oparciu o układy FPGA i mikroprocesory MPU. Co więcej, stosunkowo proste aplikacje, takie jak monitorowanie i analiza drgań (na przykład w konserwacji predykcyjnej), można zrealizować nawet w 8-bitowym mikrokontrolerze.
Co więcej, o ile początkowo użycie ML/AI wymagało posiadania wykwalifikowanych analityków danych zajmujących się opracowywaniem algorytmów rozpoznawania wzorców – oraz modeli, które można było automatycznie aktualizować w celu tworzenia prognoz – o tyle obecnie sytuacja ta jest już inna. Inżynierowie systemów wbudowanych, znający się już na przetwarzaniu brzegowym, dysponują obecnie komponentami, oprogramowaniem i narzędziami umożliwiającymi projektowanie urządzeń z algorytmami ML/AI. Ponadto wiele modeli i danych treningowych jest dostępnych bezpłatnie, a liczni dostawcy układów scalonych oferują zintegrowane środowiska programistyczne (IDE) i biblioteki, które przyspieszają tworzenie aplikacji ML/AI.
Weźmy na przykład środowisko IDE MPLAB X firmy Microchip. Ten program zawiera narzędzia ułatwiające konfigurowanie, projektowanie, debugowanie i kwalifikowanie projektów systemów wbudowanych z użyciem dla wielu chipów firmy Microchip. Wtyczka do pakietu uczenia maszynowego umożliwia zapis modeli uczenia maszynowego bezpośrednio w docelowej platformie sprzętowej. Pakiet ten wykorzystuje tzw. automatyczne uczenie maszynowe (AutoML), czyli proces automatyzacji wielu czasochłonnych i iteracyjnych zadań, takich jak tworzenie i trenowanie modeli (patrz rys. 1).
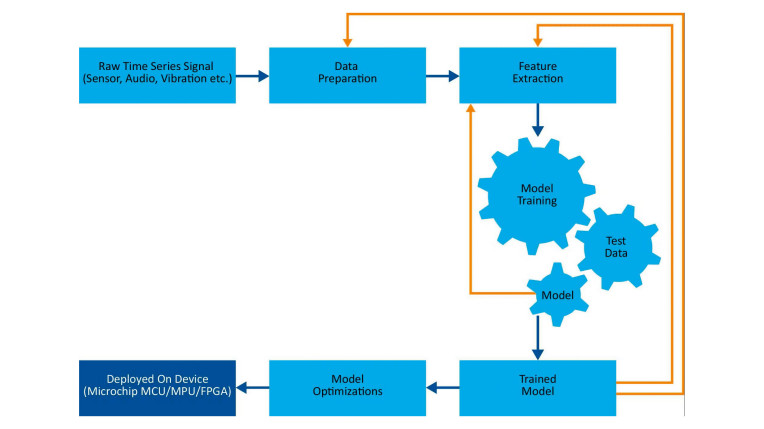
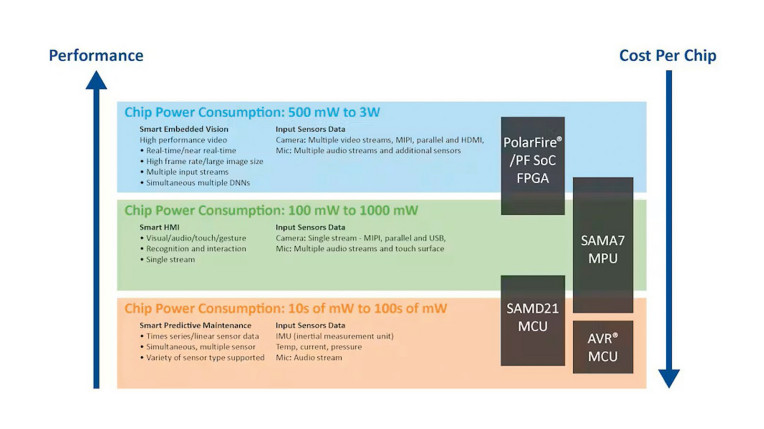
Chociaż procedurę pokazaną na rysunku 1 można zautomatyzować, optymalizacja projektu to zupełnie inna sprawa. Nawet doświadczeni specjaliści w projektowaniu aplikacji przetwarzania brzegowego mogą mieć trudności z niektórymi aspektami ML/AI. Konieczne będzie dokonanie wielu kompromisów między wydajnością systemu (w dużej mierze uwarunkowaną rozmiarem/złożonością modelu i ilością danych), zużyciem energii i kosztami. Odnośnie do tych dwóch ostatnich czynników, rysunek 2 ilustruje odwrotną zależność między wymaganą wydajnością a kosztami oraz wskazuje zużycie energii dla grup układów firmy Microchip używanych w typowych aplikacjach ML.
Projektowanie dla Small Form Factors (SFF)
Jak wspomniano, nawet mikrokontrolery 8-bitowe mogą być używane w niektórych aplikacjach uczenia maszynowego (ML). Jednym z czynników, które to umożliwiają i w znacznym stopniu przyczyniają się do wprowadzenia uczenia maszynowego/sztucznej inteligencji (ML/AI) do społeczności inżynierskiej, jest popularność technologii tinyML, która pozwala na uruchamianie modeli na jednostkach o ograniczonych zasobach.
Zalety tego rozwiązania widać, biorąc pod uwagę, że wysokiej klasy mikrokontroler (MCU) lub mikrokontroler (MPU) do aplikacji uczenia maszynowego/sztucznej inteligencji (ML/AI) zazwyczaj pracuje z częstotliwością od 1 do 4 GHz, potrzebuje od 512 MB do 64 GB pamięci RAM i wykorzystuje od 64 GB do 4 TB pamięci nieulotnej. Pobiera również od 30 do 100 W mocy. Z kolei tinyML jest przeznaczony dla mikrokontrolerów pracujących z częstotliwością od 1 do 400 MHz, mających od 2 do 512 KB pamięci RAM i wykorzystujących od 32 KB do 2 MB pamięci nieulotnej (NVM) do przechowywania danych. Pobór mocy wynosi zazwyczaj od 150 μW do 23,5 mW, co jest wartością idealną w przypadku zastosowań zasilanych bateryjnie.
Kluczem do wdrożenia tinyML jest opanowanie gromadzenia i przygotowywania danych oraz generowanie informacji do ulepszania modelu. Z tych etapów gromadzenie i przygotowywanie danych są niezbędne, aby wartościowe informacje (zestaw danych) były dostępne w całym procesie uczenia maszynowego (patrz rys. 3).

Do celów szkoleniowych potrzebne są zbiory danych dla maszyn nadzorowanych (i półnadzorowanych). W tym przypadku zbiór danych to zbiór danych, który jest już uporządkowany. Jak wspomniano, w systemach nadzorowanych dane są etykietowane, więc w przykładzie z inteligentną kamerą bezpieczeństwa automat byłby trenowany na podstawie zdjęć m.in. osób stojących, chodzących i biegnących. Zbiór danych można by stworzyć ręcznie, choć wiele z nich jest dostępnych komercyjnie, na przykład MPII Human Pose, który zawiera około 25 000 obrazów wyodrębnionych z dostępnych online filmów.
Taki zbiór wymaga jednak optymalizacji. Zbyt duża ilość danych szybko zapełni dostępną pamięć. Zbyt mała ilość sprawi, że algorytm albo nie będzie w stanie formułować prognoz, albo będą one błędne.
Ponadto sam model ML/AI musi być mały. W tym kontekście jedną z popularnych metod kompresji jest przycinanie "weight pruning", w którym waga połączeń między niektórymi neuronami w modelu jest ustawiona na zero, co oznacza, że maszyna nie musi ich uwzględniać podczas wnioskowania z modelu. Neurony również mogą być przycinane. Inną techniką kompresji jest kwantyzacja. Zmniejsza ona precyzję parametrów, odchyleń i aktywacji modelu poprzez konwersję danych w formacie o wysokiej precyzji, takim jak 32-bitowa liczba zmiennoprzecinkowa (FP32), do formatu o niższej precyzji, na przykład 8-bitowej liczby całkowitej (INT8).
Zoptymalizowany zbiór danych i kompaktowy model ułatwiają wybór odpowiedniego mikrokontrolera. Są też pomocne frameworki – na przykład TensorFlow Framework umożliwia wybór nowego modelu TensorFlow lub ponowne trenowanie istniejącego. Następnie można go skompresować do postaci płaskiego bufora za pomocą konwertera TensorFlow Lite, załadować do systemu i skwantyzować.

Podsumowanie
Uczenie maszynowe (ML) i sztuczna inteligencja (AI) wykorzystują metody algorytmiczne do identyfikacji wzorców/trendów w danych i do tworzenia prognoz. Dzięki umieszczeniu algorytmu ML/ AI na krawędzi systemu aplikacje mogą wnioskować i sterować w czasie rzeczywistym, co zwiększa wydajność i bezpieczeństwo całego systemu.
Dzięki dostępności odpowiedniego sprzętu, środowisk programistycznych (IDE), narzędzi i zestawów programistycznych, frameworków, zestawów danych i modeli open source inżynierowie mogą stosunkowo łatwo tworzyć produkty do przetwarzania brzegowego z obsługą uczenia maszynowego (ML/AI).
Yann LeFaou, Microchip Technology
www.microchip.com












