
Rynek tzw. inteligentnych czujników rozrasta się w bardzo szybkim tempie. Przyjmuje się, że w 2018 roku jego wartość wyniosła ok. 31 mld dol., zaś zgodnie z prognozami do roku 2024 powinna osiągnąć około 90 mld dol., wzrastając w ciągu 6 lat niemal trzykrotnie. Daje to imponujące roczne tempo wzrostu o wartości ok. 18%. Wraz z ogromną i wciąż rosnącą we współczesnym świecie rolą takich rozwiązań jak systemy IoT, pojazdy autonomiczne oraz urządzenia mobilne, czujniki MEMS postrzegane są jako komponenty o kluczowym znaczeniu, niezbędne do prawidłowego działania wielu różnych typów urządzeń.
Urządzenia i systemy wykorzystujące technologię MEMS znalazły zastosowanie w niemal wszystkich obszarach nowoczesnej gospodarki, jako elementy infrastruktury oraz wyposażenia miast, pojazdów, budynków oraz wszelkiego typu inteligentnych systemów. Wraz ze wzrostem ilości danych generowanych przez te czujniki, gwałtownie wzrastają również wymagania i zdolności niezbędne do ich przetwarzania. W przypadku wielu rozbudowanych systemów grozi to przekroczeniem możliwości obliczeniowych oferowanych przez technologie oparte na chmurze. Groźba ta wynika z dwóch powodów – konieczności przesłania ogromnej ilości rejestrowanych danych w czasie zbliżonym do rzeczywistego oraz podobnie szybkiego ich przetworzenia. Jednym ze sposobów na eliminację tego typu problemów jest przeniesienie części procesu przetwarzania oraz obróbki danych do układów embedded. W tym celu wykorzystać można techniki i metody uczenia maszynowego, co omówione zostanie w dalszej części tekstu.
Uczenie maszynowe oraz algorytmy sztucznej inteligencji
Uczenie maszynowe jest jednym z obszarów badań odnoszących się do teorii i technik sztucznej inteligencji. Zagadnienie to koncentruje się na zapewnieniu systemom cyfrowym zdolności do uczenia, rozumianego jako poprawa efektywności algorytmów decyzyjnych na podstawie doświadczenia zdobywanego poprzez interakcję programu ze zbiorem danych, nie zaś, jak w przypadku programów opartych na podejściu klasycznym, poprzez bezpośrednie modyfikacje kodu źródłowego przez programistę.
Proces uczenia oparty jest na swoistej kombinacji wyników obserwacji, otrzymanych instrukcji oraz zbioru danych wejściowych. Dane są przetwarzane w celu ekstrakcji wzorców, które mogą być później wykorzystane do poprawy efektywności działania algorytmu, a zatem uzyskania zdolności wypracowywania lepszych i bardziej trafnych decyzji. Metoda ta pozwala na automatyzację procesu ciągłego ulepszania programu, wymagając przy tym jedynie minimalnej interwencji programisty. W dużym uproszczeniu można nawet stwierdzić, że algorytmy uczenia maszynowego pozwalają urządzeniom oraz systemom samodzielnie się programować oraz poprawiać efektywność działania poprzez proces ciągłego samodoskonalenia.

W konwencjonalnych systemach program wykorzystuje dane wejściowe do wypracowania określonego wyniku. Jakikolwiek błąd lub niedoskonałość programu wymaga interwencji programisty, polegającej na wprowadzeniu zmian w kodzie źródłowym. Podejście to stosowane jest od samych początków epoki obliczeń komputerowych. W przeciwieństwie do tego, w rozwiązaniach używających algorytmów uczenia maszynowego to właśnie dane wejściowe oraz rzeczywiste i pożądane dane wyjściowe stosowane są do skonstruowania programu. Oba te podejścia mogą być wykorzystywane wspólnie w jednym systemie – zazwyczaj algorytmy uczenia maszynowego stosuje się do realizacji zadań polegających na rozpoznawaniu oraz klasyfikacji zbiorów danych.
Dzięki rosnącym możliwościom sprzętowym współczesnych mikroprocesorów oraz coraz bardziej rozwiniętym narzędziom projektowym technologia uczenia maszynowego zaczyna być powszechnie stosowana w wielu zadaniach, takich jak np. rozpoznawanie twarzy oraz mowy, wypracowywanie optymalnych decyzji, diagnostyki urządzeń czy też realizacji strategii marketingowych.
Algorytmy uczenia maszynowego podzielić można na trzy główne kategorie: uczenie nadzorowane (supervised learning), uczenie nienadzorowane (unsupervised learning) oraz uczenie ze wzmocnieniem (reinforcement learning).
Uczenie nadzorowane opiera się na odpowiednim oznaczeniu zbioru danych wejściowych. Nauczany system otrzymuje zestawy danych wejściowych wraz z odpowiednią klasyfikacją lub zestawem reguł definiujących pożądaną wartość danych wyjściowych. Maszyna uczy się zatem na podstawie opisanych przykładów, definiując określone wzorce obiektów, co pozwala jej następnie dopasowywać dane rzeczywiste do tych wzorców. Tego rodzaju podejście wykorzystywane jest m.in. w systemach rozpoznawania twarzy, mowy czy też np. do kategoryzacji zbiorów danych na podstawie znanych cech i charakterystyk obiektów. Podstawowym problemem przy tego rodzaju technice jest konieczność dysponowania dobrze opisanym zbiorem danych wejściowych.
Uczenie nienadzorowane polega na dostarczeniu na wejście maszyny zbioru samych tylko danych wejściowych (charakterystyk), bez zdefiniowania oczekiwanych wartości wyjścia. Algorytmy uczenia nienadzorowanego pozwalają na pogrupowanie tych danych na podstawie zidentyfikowanych cech wspólnych oraz wyznaczenie wzorca dla każdej z otrzymanych grup. Tego typu algorytmy świetnie nadają się do przetwarzania dużych zbiorów nieopisanych danych, często pozwalając na znalezienie bardzo interesujących trendów oraz zależności, znajdują również zastosowanie m.in. w marketingu (segmentacja klientów, systemy rekomendacyjne), systemach transakcyjnych czy diagnostycznych (wykrywanie anomalii).
Uczenie ze wzmocnieniem wykorzystuje się w celu wypracowania optymalnego sposobu działania w obrębie już ustalonych reguł. Ten przypadek uczenia maszynowego wymaga istnienia funkcji wzmocnienia, będącej czymś na podobieństwo zjawiska sprzężenia zwrotnego – wartość funkcji wzmocnienia zmienia się wskutek podjętych przez algorytm działań. Jeśli działania te są poprawne, wartość funkcji wzmocnienia rośnie, jeśli błędne, to maleje. Tego typu techniki stosuje się m.in. w systemach wspomagających podejmowanie decyzji w czasie rzeczywistym, jako algorytmy sterujące zachowaniem sztucznej inteligencji w grach komputerowych czy też w autonomicznych systemach nawigacyjnych.
Prawdopodobnie najbardziej rozwiniętym, najlepiej znanym i najpowszechniej wykorzystywanym rodzajem uczenia maszynowego jest uczenie nadzorowane. Jest to zapewne związane z faktem, że technika ta jest najbardziej intuicyjna (bardzo zbliżona do sposobu nauki preferowanego przez ludzki umysł) i najprostsza w implementacji.
Przygotowanie danych treningowych
Bez względu na wybraną odmianę uczenia maszynowego, zagadnieniem kluczowym do osiągnięcia dobrej dokładności i skuteczności algorytmu jest właściwe przygotowanie danych treningowych. Informacje te muszą być reprezentatywne, to znaczy zawierać możliwie dużą liczbę potencjalnych rzeczywistych przypadków, wartości granicznych oraz szczególnych, muszą być również odpowiednio posegregowane oraz opisane. Proces przygotowania danych treningowych jest wieloetapowy. Powinien rozpocząć się od zebrania danych, następnie ich oczyszczenia, czyli usunięcia błędnych rekordów oraz duplikatów, a także uzupełnienia brakujących wpisów. W niektórych przypadkach konieczna może być konwersja wartości (np. przeliczenie jednostek pomiarowych) lub normalizacja wyników. Dane powinny być opisane w przejrzysty i ujednolicony sposób, co umożliwia ich późniejszą klasyfikację. Klasyfikacja obejmuje identyfikację cech charakterystycznych obiektów, oznaczenie ich oraz stworzenie zestawu określonych reguł definiujących przynależność do poszczególnych klas. W przypadku niektórych rodzajów algorytmów uczących trenowany system jest w stanie samemu stworzyć własne reguły definiujące zidentyfikowane grupy obiektów. Analizując duże zbiory danych, system dostrzega podobieństwa pomiędzy poszczególnymi rekordami i na tej podstawie grupuje je w podzbiory. Jeśli dane treningowe nie zostaną przygotowane w prawidłowy i staranny sposób, bardzo trudne będzie uzyskanie zadowalających wyników działania algorytmu uczącego.

Podstawą dobrze przygotowanego zbioru danych treningowych jest nie tylko staranne opisanie oraz oczyszczenie zebranych rekordów, ale również (a nawet przede wszystkim) odpowiedni dobór przypadków treningowych. Jeśli celem treningu jest nauczenie systemu rozpoznawania obiektów i przypisywania ich do jednej ze skończonej liczby kategorii, dane treningowe powinny obejmować odpowiednią liczbę przykładów dla każdej z kategorii. Liczba przypadków zależy od liczby cech obiektu podlegających analizie. Jeśli cechy te w rzeczywistości nie są skorelowane, czyli wartość każdej nich nie jest zależna od żadnej innej, to należy uważać, aby nie uzyskać przypadkowej korelacji wśród danych treningowych. Również sam dobór cech jest zadaniem nieoczywistym i w dużej mierze determinującym końcową skuteczność algorytmu. Powinno się generalnie unikać cech skorelowanych ze sobą, jak również niewnoszących zbyt wiele informacji czy też niepozwalających na rozróżnienie pomiędzy poszczególnymi grupami obiektów. Zbyt duża liczba stopni swobody modelu (zbyt wiele analizowanych parametrów obiektu w stosunku do zawartości informacyjnej danych) może doprowadzić do zjawiska przetrenowania, obniżającego skuteczność modelu w odniesieniu do danych rzeczywistych. Przetrenowanie prowadzi do zaniku zdolności modelu do generalizacji, czyli rozpoznawania i klasyfikacji danych w pewnym zakresie podobnych do występujących w zbiorze uczącym.
Przetrenowanie oraz niedopasowanie modelu
Jednym z parametrów opisujących skuteczność modelu jest jego dopasowanie do danych treningowych. Jeśli dopasowanie modelu jest zbyt duże lub zbyt małe, istnieje znaczące ryzyko, że nie będzie skutecznie radził sobie w warunkach rzeczywistej pracy. W praktyce nieodpowiednie dopasowanie jest jedną z głównych przyczyn słabej efektywności algorytmów uczenia maszynowego. Zjawiska te przedstawiono na rysunku 2. Model powstały w wyniku procesu uczenia maszynowego przyrównać można do wielomianu będącego interpolacją zbioru danych (punktów) treningowych. Im wyższy stopień wielomianu, tym lepsza dokładność modelu dla danych uczących (węzłów interpolacji), efektem ubocznym może być jednak nietypowe zachowanie (duża zmienność) funkcji opisującej wielomian pomiędzy poszczególnymi węzłami. W efekcie model będzie charakteryzował się bardzo dobrą dokładnością dla zbioru uczącego, jednocześnie słabo radząc sobie z danymi rzeczywistymi.
Efekt niedopasowania jest przypadkiem odwrotnym do uprzednio opisanego – opisanie modelu za pomocą wielomianu o zbyt małym stopniu powoduje niemożliwość właściwego odwzorowania rzeczywistych cech opisywanego zjawiska. Tego typu problem jest jednak znacznie łatwiejszy do wykrycia, ponieważ model charakteryzujący się niedopasowaniem daje słabe rezultaty zarówno dla zbioru danych uczących, jak i w warunkach rzeczywistych.
W celu uniknięcia nadmiernego dopasowania konieczne jest zastosowanie dodatkowych zabiegów sprawdzających efektywność modelu. Jedną z najpopularniejszych jest tzw. walidacja krzyżowa. W najprostszej wersji tej techniki zbiór danych wejściowych dzieli się na dwa podzbiory: uczący oraz testowy. Zbiór uczący wykorzystywany jest następnie do treningu systemu. Po wykonaniu odpowiedniej liczby cykli treningowych iteracyjnie sprawdzana jest dokładność modelu zarówno dla zbioru uczącego, jak i testowego. Zazwyczaj szkolenie przerywa się w momencie, kiedy błąd dokładności modelu uzyskany dla zbioru testowego zaczyna wzrastać, nawet jeśli błąd dla zbioru uczącego wciąż maleje.
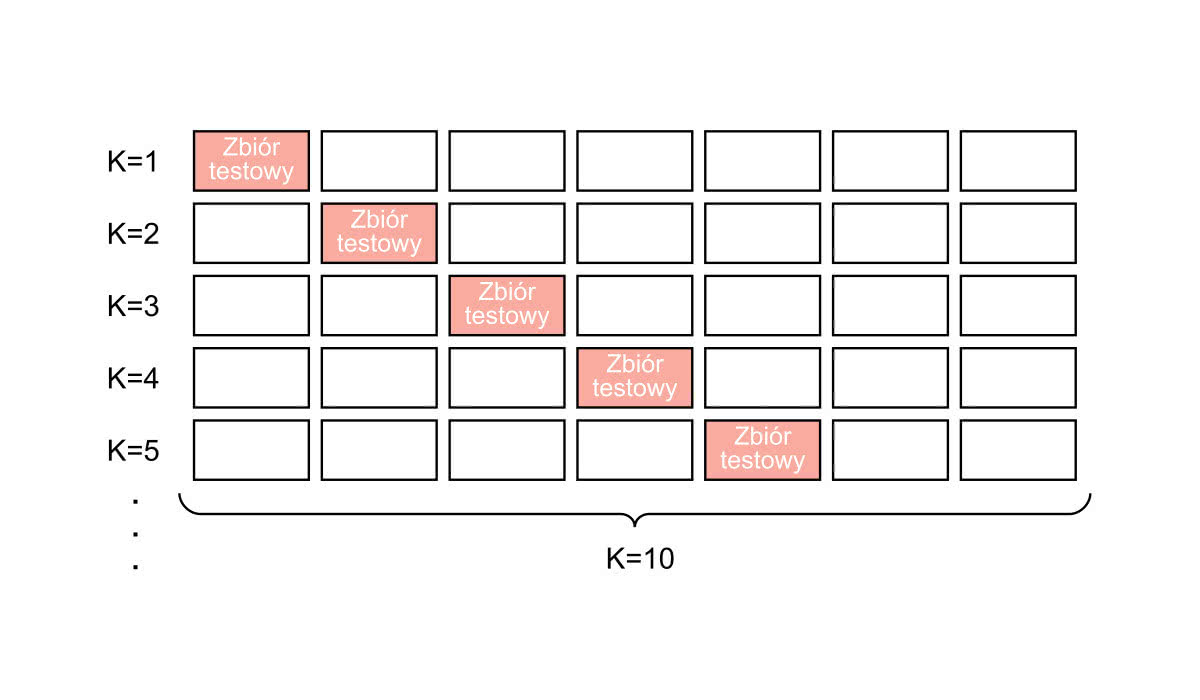
W bardziej rozbudowanej wersji, określanej jako K-krotna walidacja, zbiór danych wejściowych dzielony jest na K podzbiorów. Każdy z nich wykorzystywany jest kolejno jako zbiór testowy, zaś wszystkie pozostałe razem tworzą zbiór uczący. Proces szkolenia wykonywany jest zatem K razy, otrzymane rezultaty są następie uśredniane w celu uzyskania wyniku końcowego. Przebieg K-krotnej walidacji krzyżowej zobrazowany został w uproszczeniu na rysunku 3.
Uczenie maszynowe dla układów MEMS
Na przestrzeni ostatnich lat dało się zaobserwować ciągły wzrost popularności układów IoT, znajdujących zastosowanie w coraz to nowych aplikacjach i obszarach. Sieci połączonych ze sobą urządzeń sterowanych za pomocą chmury lub zdalnego serwera wykorzystywane są do zarządzania budynkami oraz obszarami, realizując przy tym zróżnicowane zadania, m.in. z zakresu bezpieczeństwa, optymalizacji zużycia zasobów czy też monitoringu otoczenia. Systemy IoT powszechnie stosowane są w przemyśle, transporcie, budownictwie czy handlu. Typowa architektura tego typu rozwiązań zakłada połączenie dużej liczby drobnych urządzeń-węzłów sieci z elementem centralnym. Węzły przesyłają do elementu centralnego zgromadzone dane, ten zaś zajmuje się ich przetwarzaniem, podejmowaniem decyzji i ewentualną komunikacją zwrotną, mogącą polegać m.in. na przesyłaniu poleceń sterujących. Podejście takie wymaga dysponowania szerokim pasmem transmisyjnym oraz dużymi zdolnościami obliczeniowymi. Element centralny jest krytycznym ogniwem całej infrastruktury – jego niewystarczająca wydajność może doprowadzić do znaczącego spowolnienia lub utraty operacyjności systemu.
Przy zachowaniu obecnego tempa wzrostu bardzo prawdopodobne jest, że zapotrzebowanie na usługi chmurowe w niedalekiej przyszłości przekroczy podaż, czyli możliwości oferowane przez dostawców tego typu usług. Aby poradzić sobie z tego typu problemami, przyszłe rozwiązania IoT będą musiały wdrożyć mechanizmy przenoszące przynajmniej część zapotrzebowania na moc obliczeniową z jednostki centralnej do węzłów sieci, przy okazji obniżając także konieczną szerokość pasma transmisyjnego.
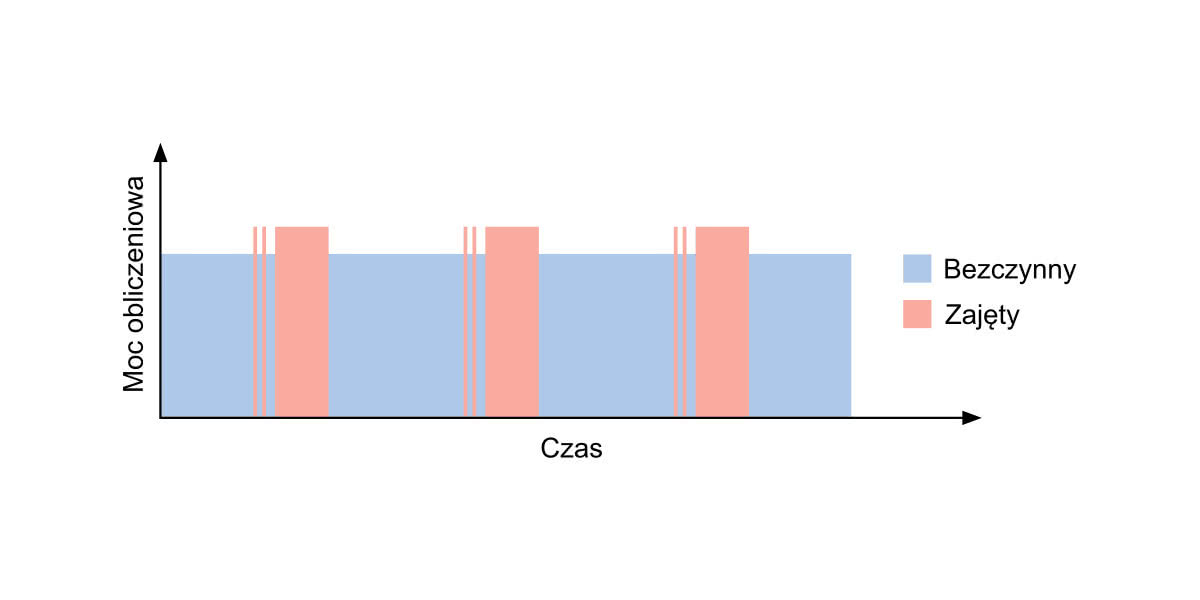
Możliwości współczesnych mikrokontrolerów w przypadku znakomitej większości typowych zastosowań pozwalają na realizację tego typu zadania. Od lat zdolności obliczeniowe tego typu układów rosną, często w połączeniu z jednoczesnym spadkiem użycia energii elektrycznej. Powszechnie stosowany model systemu IoT powoduje jednak, że układy te w większości przypadków nie muszą robić niemal nic więcej poza zebraniem danych z podłączonych do nich czujników oraz przesłaniem ich za pomocą określonego protokołu komunikacyjnego do chmury. Przez większość czasu pracy mikrokontroler pozostaje zatem w trybie bezczynności, wykorzystując jedynie ułamek dostępnego budżetu mocy obliczeniowej. Sytuacja ta zobrazowana została na rysunku 4. Obszary różowe symbolizują okresy aktywności mikrokontrolera, wykonującego w tym czasie różne zadania, takie jak zebranie danych, obsługa komunikacji oraz układów peryferyjnych. Obszary niebieskie oznaczają czas bezczynności, kiedy to dostępna moc obliczeniowa nie jest wykorzystywana. Setki milionów tego typu urządzeń rozmieszczonych w rzeczywistym świecie oznaczają istnienie ogromnych i wciąż niewykorzystywanych pokładów zdolności obliczeniowych.
Podejście polegające na bardziej rozproszonym wykorzystaniu zasobów sieci IoT pozwala znacząco obniżyć zarówno wymagane pasmo transmisji danych, jak i obłożenie chmury. Z punktu widzenia użytkowników może być to również korzystne dla zachowania bezpieczeństwa oraz prywatności ich danych. Analiza i przetworzenie danych już na poziomie węzła sieci umożliwia dostarczenie ich do serwera w bardziej anonimowej formie.
Na rynku spotkać można już modele czujników MEMS wyposażone w układy uczenia maszynowego. Układ taki dokonuje ekstrakcji wybranych parametrów sygnału pomiarowego (jak np. średnia, wartość minimalna, maksymalna czy też wariancja), następnie zaś traktuje te wartości jako dane wejściowe algorytmu klasyfikującego. Za pomocą odpowiedniego zestawu danych treningowych można zatem nauczyć sensor rozpoznawania np. określonych typów aktywności czy rodzajów pracy. W przypadku czujników inercyjnych (żyroskop, akcelerometr) może to pozwolić na przeniesienie zadania rozpoznawania rodzaju aktywności fizycznej wykonywanej przez użytkownika już nie tylko na poziom mikroprocesora, lecz na poziom czujnika. Efektem końcowym procesu uczenia maszynowego jest drzewo decyzyjne, opisujące algorytm klasyfikacyjny wykorzystywany przez czujnik. Drzewo takie może być wgrywane do innych czujników oraz dowolnie modyfikowane.
Możliwa jest również implementacja algorytmów uczenia maszynowego bezpośrednio w mikrokontrolerze, choć w przypadku braku dedykowanych układów sprzętowych efektywność tego rozwiązania jest dość ograniczona. Istnieją jednak programowe biblioteki przeznaczone do popularnych modeli mikroprocesorów, np. dla produktów z rodziny Arduino oraz układów ARM. W takich przypadkach najbardziej efektywne jest przeprowadzenie procesu uczenia, wymagającego dużych zasobów obliczeniowych, w sposób offline, czyli na innym urządzeniu, np. komputerze, a następnie wgranie uzyskanych wyników do układu docelowego.
Podsumowanie
Technologia uczenia maszynowego znalazła zastosowanie w wielu różnych dziedzinach, skutecznie konkurując i zastępując rozwiązania oparte na klasycznym oprogramowaniu. Świetnie sprawdza się w zadaniach polegających na rozpoznawaniu wzorców, klasyfikacji i grupowaniu danych oraz przetwarzaniu i integracji sygnału z czujników. Jednym z obszarów zastosowań tego typu algorytmów jest świat systemów IoT, zbudowany z sieci rozproszonych sensorów przesyłających dane do chmury w celu ich analizy oraz przetworzenia.

Rosnący rozmiar systemów IoT przekłada się na coraz większą liczbę gromadzonych, przesyłanych oraz przetwarzanych danych. Zwiększa to wymagania odnośnie do przepustowości oraz zdolności obliczeniowych dla systemów chmurowych, niekiedy w stopniu zagrażającym utrzymaniu ich wysokiej wydajności. Rozwiązaniem tego problemu jest przeniesienie części zadań związanych z przetwarzaniem danych do węzłów sieci – mikrokontrolerów lub nawet czujników. Na rynku znaleźć można już czujniki MEMS wyposażone w dedykowane sprzętowe moduły sieci neuronowych, pozwalające na implementację algorytmów uczenia maszynowego. Częściowe przetworzenie danych bezpośrednio na poziomie czujnika lub mikroprocesora znacząco poprawia też bezpieczeństwo systemu i stopień ochrony prywatności użytkowników, ponieważ eliminuje potrzebę przesyłania surowych danych, z natury rzeczy wysoce spersonalizowanych, umożliwiając zastąpienie ich bardziej anonimowymi wynikami uzyskanymi w procesie przetwarzania.
Damian Tomaszewski










