
W rozwój duże sumy inwestuje biznes i władze administracyjne wielu krajów. Coraz bardziej dostępne i zaawansowane narzędzia AI/ML pomagają osobom niebędącym analitykami danych w zrozumieniu, tworzeniu i wdrażaniu modeli procesów. Chociaż budowanie modelu z uwagi na wymaganą moc obliczeniową odbywa się w chmurze, a więc na bazie wydajnych maszyn, w praktyce często zachodzi potrzeba przeprowadzania wnioskowania lokalnie – tzw. na krawędzi. Ma to kilka zalet, w tym zawiera się większe bezpieczeństwo, ponieważ nie komunikujemy się ze światem zewnętrznym. Działając lokalnie, nie zużywamy też przepustowości łącza na przesyłanie danych do chmury, a następnie odbieranie wyników. Inne korzyści to na przykład:
- działanie w czasie rzeczywistym/natychmiastowa reakcja urządzenia na zdarzenia – małe opóźnienie, bezpieczna praca
- mniejszy koszt – efektywne wykorzystanie przepustowości łącza
- niezawodne działanie przy problemach z komunikacją
- lepsze doświadczenie użytkownika
- lepsza prywatność i większa ochrona danych – mniej danych do przesłania prowadzi do zwiększenia prywatności
- mniejsze zużycie energii – nie ma potrzeby korzystania z wydajnej komunikacji
- lepsza wydajność dzięki indywidualnemu uczeniu się cech każdego produktu
Wymagane małe opóźnienie w reakcji jest dobrą wskazówką do tego, aby w aplikacji przeprowadzać wnioskowanie lokalnie, ponieważ dzięki temu nie trzeba czekać na przesłanie informacji do chmury i odesłanie wyników. Przeniesienie uczenia maszynowego z wydajnych komputerów na wysokiej klasy mikrokontrolery jest możliwe już dzisiaj i warto sięgnąć po takie możliwości.
Czym jest sztuczna inteligencja i uczenie maszynowe?
Sztuczna inteligencja powstała w latach 50. ubiegłego wieku. Zastępuje ona procedurę programowania, opracowując algorytmy oparte na danych, zamiast korzystania ze starszej metody zapisywania ich w kodzie. Uczenie maszynowe to z kolei podzbiór sztucznej inteligencji, w którym komputer próbuje wydobyć informacje z analizy zbioru danych. Dostarczamy maszynie surowe dane, a następnie komputer tworzy algorytm, który jest w stanie przewidzieć wyniki dla nowego zbioru danych.
Proces ten opiera się na czymś, co nazywa się "uczeniem nadzorowanym". W tej technice dane są etykietowane (kategoryzowane), a wyniki są oparte na tym etykietowaniu. Model procesu też jest tworzony na podstawie tego etykietowania. Inną techniką jest głębokie uczenie, które działa na bardziej złożonych algorytmach, w których dane nie są etykietowane (podpisywane). W tym artykule zajmujemy się tym pierwszym.
Podstawowym elementem ML jest sieć neuronowa, która składa się z warstw węzłów, z których każdy ma połączenie albo z wejściami, albo z kolejnymi warstwami. Istnieje kilka typów sieci neuronowych. Im bardziej będziemy przechodzić od uczenia maszynowego do uczenia głębokiego, tym sieci będą bardziej złożone. Głębokie uczenie zawiera również mechanizmy sprzężenia zwrotnego, podczas gdy proste modele ML nie korzystają z tego – działają wprost, przechodząc od danych wejściowych do wyniku.
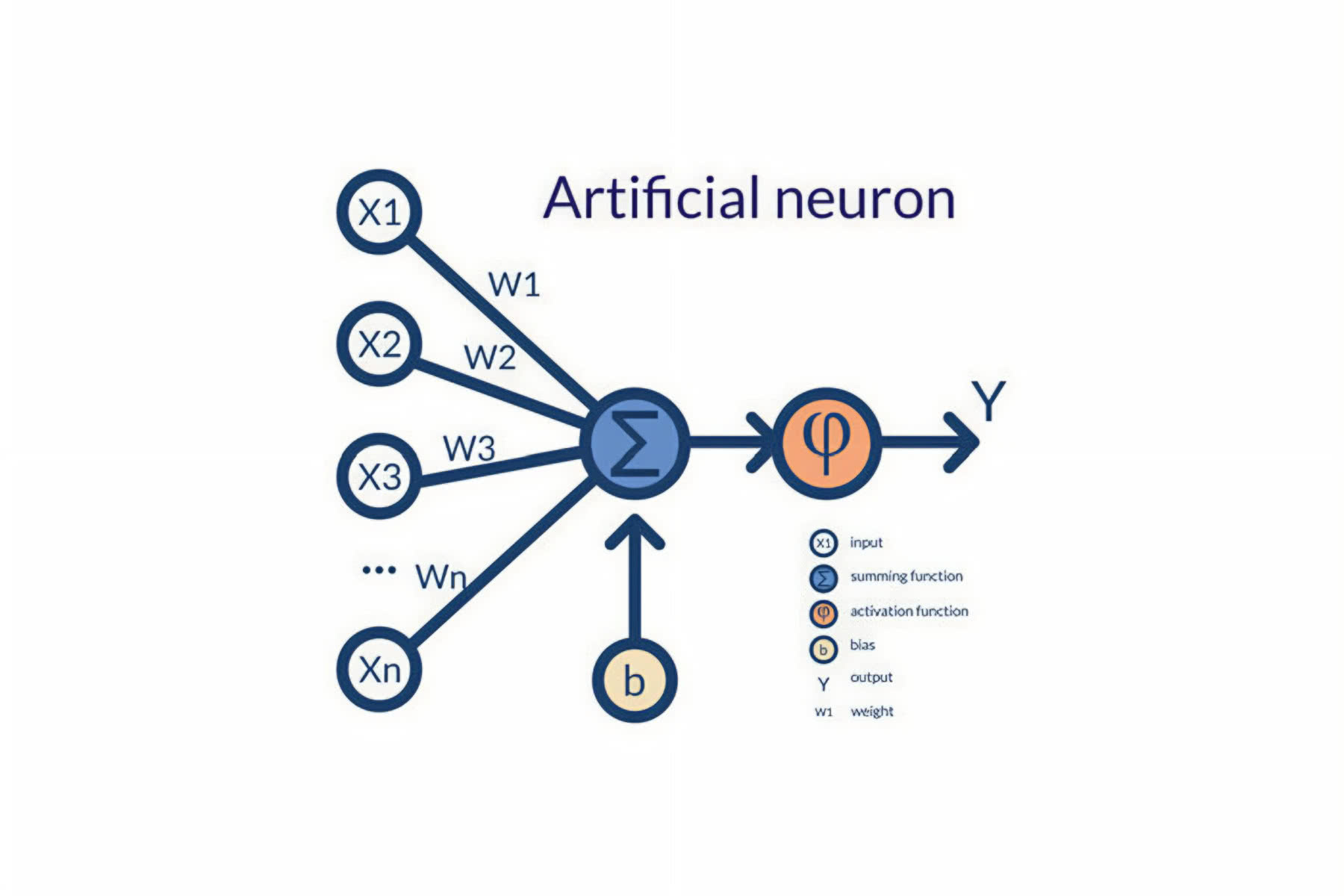
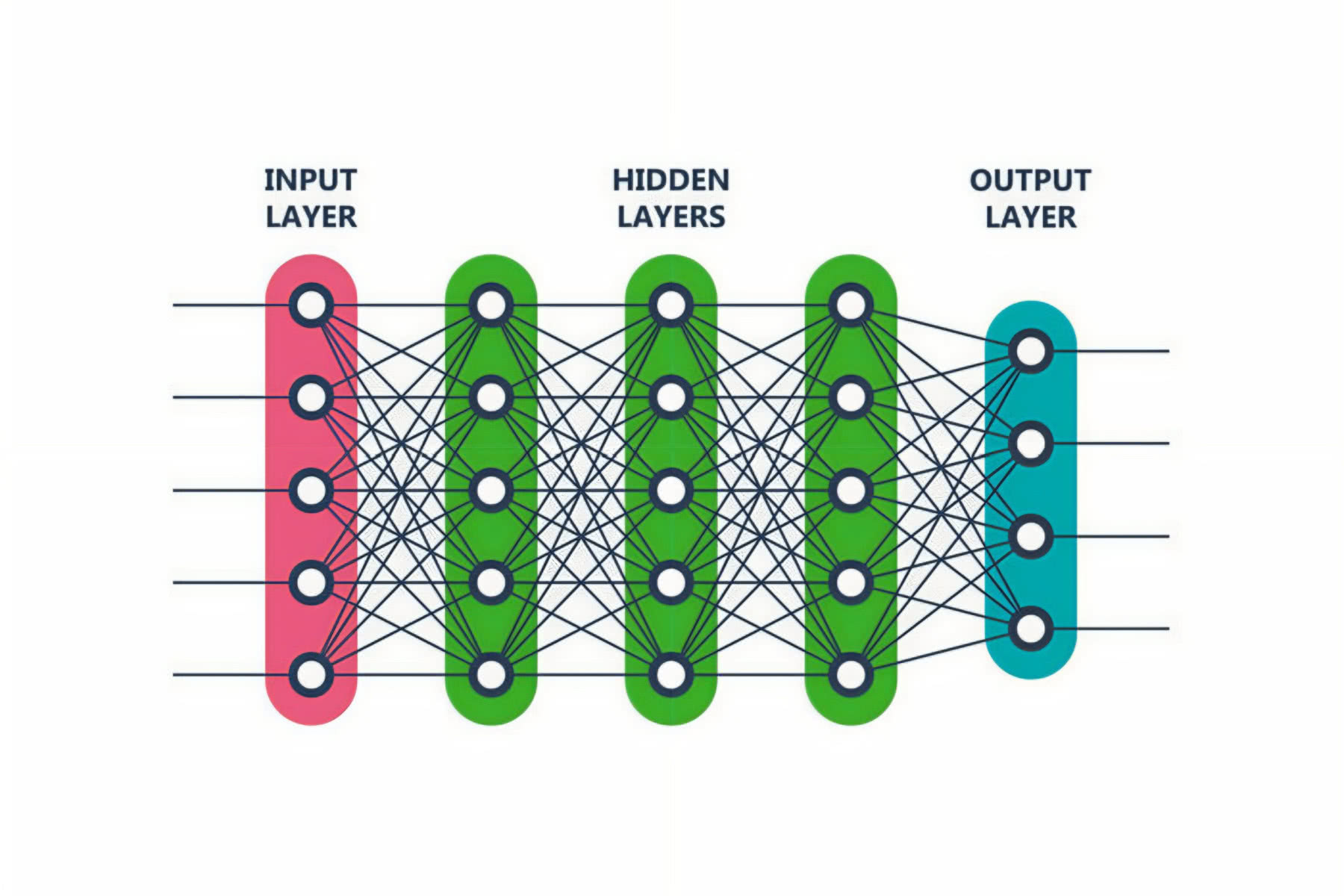
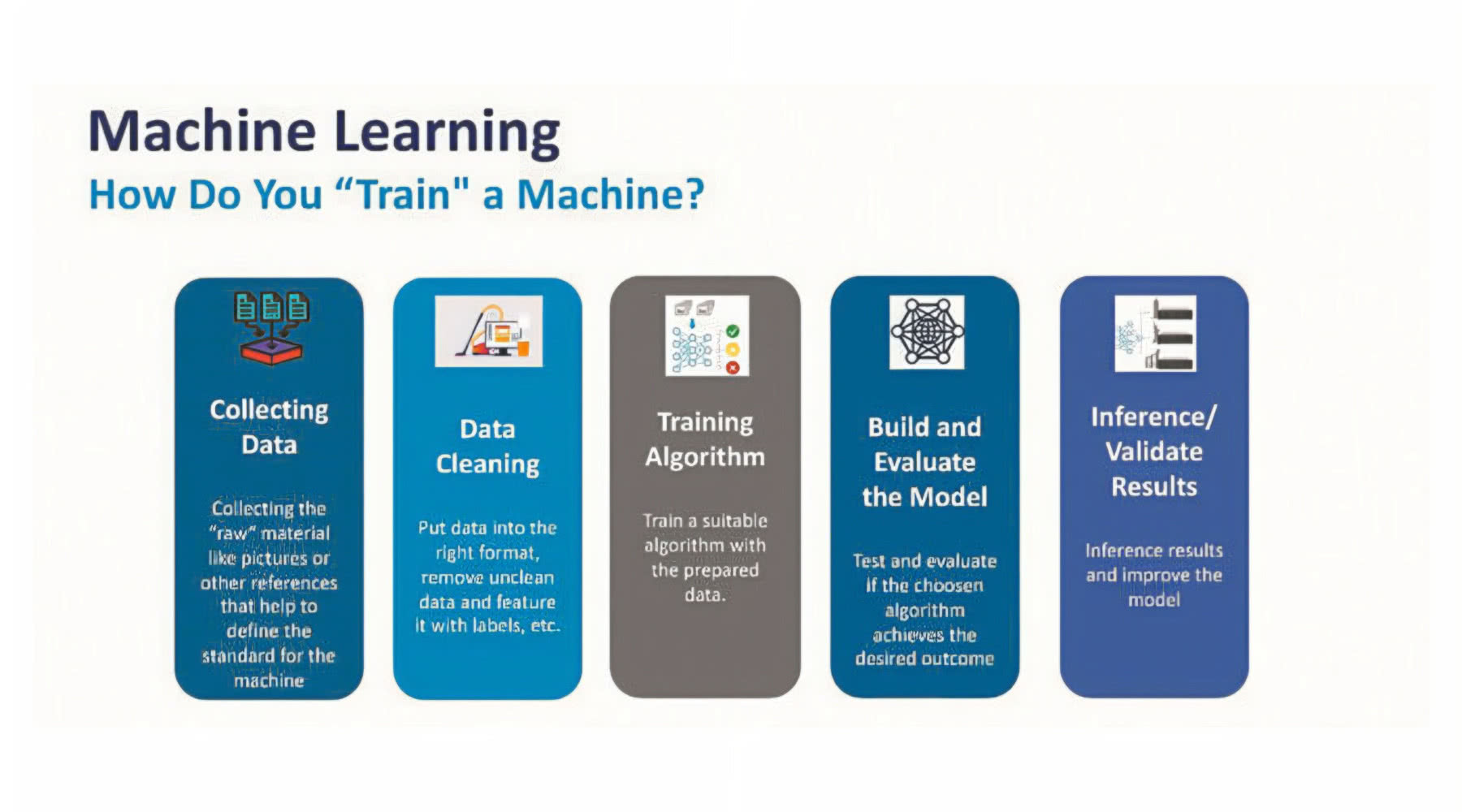
Jak trenować maszynę?
Pierwszym krokiem jest zbieranie danych. W uczeniu nadzorowanym gromadzimy skategoryzowane dane, aby można było w następnej kolejności znaleźć wzorce. Jakość danych określa, jak dokładny będzie model, stąd istotne jest, aby dane treningowe były zbierane losowo. Gdy są zbyt dobrze zorganizowane, modele nie będą tworzone poprawnie.
Drugim krokiem jest wyczyszczenie zbioru i usunięcie niechcianych informacji. Każdy niekompletny zestaw powinien zostać usunięty, a wszelkie stany, w których są niepotrzebne dane, również powinny zostać usunięte.
Dane należy następnie podzielić na dwie części, jedną do uczenia, a drugą do testowania.
Kolejnym krokiem jest uczenie algorytmu, które podzielone jest na trzy etapy. Pierwszy to wybór algorytmu klasyfikacji uczenia maszynowego. Dostępnych jest kilka, które są odpowiednie dla różnych typów danych, jak:
- Bonsai,
- zespół drzew decyzyjnych,
- wzmocniony zespół drzew,
- TensorFlow Lite dla mikrokontrolerów,
- PME.
Ważne jest, aby wybrać odpowiedni, ponieważ determinuje to wynik, jaki otrzymuje się po uruchomieniu algorytmu ML na zbiorze danych. Wybór może być dokonany poprzez analizę danych lub można skorzystać z dostępnych narzędzi analitycznych.
Drugim podetapem jest iteracyjne uczenie modelu w celu regulacji wag różnych warstw i ogólnej dokładności modelu. W trzecim kroku następuje ocena stworzonego modelu za pomocą testowania na podzbiorze danych, który wcześniej został zachowany do tego celu. Dla maszyny jest to zbiór wcześniej nieznany i stąd pozwala on porównać dane wyjściowe uzyskane z niego z innymi wynikami.
Po wykonaniu tych czynności można użyć utworzonego modelu i zweryfikować wyniki, przeprowadzając wnioskowanie, czy spełnia on oczekiwania. Chodzi o to, aby wprowadzić rzeczywiste dane wejściowe i sprawdzić, czy wyniki są prawidłowe.
Oprogramowanie narzędziowe
W przedmiotowej tematyce firma Microchip współpracuje z kilkoma partnerami, jak Edge Impulse, Motion Gestures i SensiML, a popularne frameworki, takie jak TensorFlow Lite For Microcontrollers, są częścią środowiska Microchip Harmony. TensorFlow Lite może być używany do tworzenia modeli ML dla wszystkich mikrokontrolerów i mikroprocesorów z portfolio produktowego firmy, z wyjątkiem jednostek 8-bitowych.
Mikrokontrolery i platformy mikroprocesorowe firmy Microchip są bazą do tworzenia wielu zaawansowanych aplikacji, takich jak na przykład inteligentne systemy wizyjne. Nadają się również do systemów analizy wibracji maszyn w celu przewidywania usterek, aparatury do pomiaru mocy zasilającej lub analizy dźwięku. Można je wykorzystać także do rozpoznawania gestów, a w połączeniu z interfejsem dotykowym do realizacji interfejsu człowiek-maszyna. Microchip dostarcza także wysokowydajne przełączniki magistrali PCI, które umożliwiają połączenie wielu procesorów graficznych po to, aby przyspieszyć uczenie modeli ML. Z kolei gromadzenie danych można przeprowadzić za pomocą mikrokontrolerów, mikroprocesorów, układów FPGA i czujników. Wszystkie są dostępne w ofercie. Walidacja danych i wnioskowanie mogą być wykonywane zarówno na mikrokontrolerach, mikroprocesorach, jak i układach FPGA. Zasoby te są kompleksowe i sprawiają, że tworzenie aplikacji wykorzystujących ML staje się łatwe do wdrożenia.
Jeśli chodzi o oprogramowanie, to oprócz wspomnianego Microchip Harmony obsługującego popularne frameworki, dzięki nawiązanej współpracy z firmami zewnetrznymi dostarczane jest oprogramowanie do realizacji uczenia maszynowego. Jednym z partnerów jest Edge Impulse, który w oparciu o TensorFlow Lite oferuje pełny potok TinyML, w którym można zbierać dane, tworzyć modele i je wdrażać. Jedną z największych zalet jest to, że kod Edge Impulse jest bezpłatny i otwarty (open source).
Kolejnym partnerem jest firma Motion Gestures, która specjalizuje się w technologiach rozpoznawaniu gestów i jej produkty mogą być wykorzystane do budowy interfejsów człowiek-maszyna tego typu. Narzędzie pozwala wdrożyć w aplikacji rozpoznawanie gestów w ciągu kilku minut, skracając czas tworzenia oprogramowania. Zapewnia również dobre wyniki detekcji, które w testach jest bliskie 100%. Są dwa sposoby korzystania z tego narzędzia: dotyk, klasyczny sposób lub detekcja ruchu z użyciem czujników inercyjnych.
Jak zacząć?
Microchip oferuje kilka zestawów ewaluacyjnych, które pomagają rozpocząć pracę z technikami AI i ML. Płytki pokazane na zdjęciu zawierają mikrokontroler SAMD21 oraz komunikację i czujniki TDK i Boscha. Jeśli chodzi o gesty ruchu, mamy płytkę demonstracyjną z SAMC21 Xplained Pro oraz panelem dotykowym QTouch, jednym z narzędzi, za pomocą których można rozpocząć wdrażanie aplikacji do rozpoznawania gestów ML. Jest też IGaT – karta graficzna z interfejsem dotykowym, która również wykorzystuje ML, jest dostarczana z gotowym oprogramowaniem firmware, które oprócz wersji demo pod kątem zastosowań w samochodach, budynkach i sprzęcie rozrywkowym zawiera przykład z rozpoznawaniem gestów.
Z kolei Adafruit EdgeBadge – Tensor- Flow Lite for Microcontrollers – to kolejny zestaw, który bezpośrednio wykorzystuje TensorFlow Lite. Zawiera 2-calowy wyświetlacz TFT. EdgeBadge może być używany przez społeczność Arduino. Dostępnych jest kilka przykładów, takich jak prezentacja generacji sinusoidy, gestów i syntezatora mowy.
Jeśli chodzi o aplikacje high-end, do dyspozycji jest zestaw wideo PolareFire z podwójnym interfejsem do kamery, MIPI, HDMI, 2 GB pamięci DDR, 4 GB SDRAM, interfejsem USB2UART i 1 GB pamięci Flash SPI.
Zapewnia on wykrywanie obiektów przy użyciu ML.

Więcej informacji: https://www.microchip.com/en-us/education/developer-help/learn-solutions/machine-learning.
Adil Yacoubi, EMEA Sr. Technical Marketing Engineer, Microchip Technology
Microchip
www.microchip.com









