
Tytułowe interfejsy użytkownika pozwalają na interakcję z urządzeniem lub aplikacją za pomocą poleceń wydawanych głosowo, zapewniając użytkownikom kontrolę nad nimi bez konieczności patrzenia na ekran. O tym, jak perspektywiczne jest to rozwiązanie, świadczy fakt, że wiodące przedsiębiorstwa technologiczne, jak Google, Amazon, Microsoft, Facebook, czy Apple, w swojej ofercie mają aplikacje asystentów głosowych i urządzenia sterowane głosowo, takie jak inteligentne głośniki, albo nad nimi pracują. Przykładami są: Alexa Amazona, Siri Apple, Asystent Google, Amazon Echo, Apple HomePod czy Google Home. Funkcja sterowania głosowego jest dostępna w urządzeniach różnych typów, w tym smartfonach, elektronice noszonej, komputerach, laptopach, urządzeniach Internetu Rzeczy, jak termostaty i lampy, smart TV.
Sterowanie głosem coraz popularniejsze
Sterowanie głosowe szybko zyskuje popularność. Z raportu Smart Audio Report Spring 2020 wynika, że 24% Amerykanów powyżej 18. roku życia, czyli około 60 milionów ludzi, ma co najmniej jeden inteligentny głośnik - dla porównania w 2019 21% dorosłych, tzn. około 53 mln ludzi, miało taki sprzęt w domu. Zwiększa się również ich liczba przypadająca na gospodarstwo domowe - w 2019 roku 21%, a w 2020 już 29% ankietowanych miało trzy lub więcej takich urządzeń. Badanie pokazało poza tym, że nawet jeśli na decyzję o zakupie inteligentnych głośników wpłynęła moda, okazują się one na tyle użyteczne, że w porównaniu z pierwszym miesiącem ich posiadania aż 40% osób korzysta z nich później równie często, a 43% nawet częściej, niż na początku.
56% użytkowników asystentów głosowych na smartfonie przyznało, że ma tę aplikację przez cały czas włączoną, żeby komendy głosowe wydawać kilka razy dziennie (2019 - 20%, 2020 - 25%). 68% pytanych przyznało, że osobiści asystenci sterowani głosem ułatwiają życie. 41% z nich nie chciałoby się już cofnąć do czasu, gdy z nich jeszcze nie korzystali. Właściciele inteligentnych głośników najczęściej głosowo aktywują odtwarzanie muzyki (85%), a korzystający z asystentów głosowych na smartfonie pytają o prognozę pogody.
Zalety sterowania głosowego
Sterowanie głosowe zyskuje popularność dzięki licznym zaletom. Przede wszystkim wydawanie poleceń głosowych jest szybsze oraz wygodniejsze niż pisanie wiadomości tekstowych. Jako intuicyjne jest też przyjaźniejsze dla osób, które z różnych powodów mają problem z obsługą urządzeń elektronicznych w tradycyjny sposób. Przykład to osoby starsze i dzieci, które już wprawdzie potrafią czytać, lecz nie mają wprawy w pisaniu - te na przykład mogą wysyłać wiadomości tekstowe do znajomych za pomocą interfejsu głosowego w smartfonie. Można oczekiwać, że dzięki temu dla pokolenia, które dopiero uczy się obsługi urządzeń mobilnych, sterowanie głosowe będzie interfejsem domyślnym, analogicznie jak dla poprzednich generacji ekrany dotykowe, a wcześniej klawiatury. Oprócz tego dzięki intuicyjności sterowanie głosowe może się przyczynić do popularyzacji nowych technologii wśród ludzi słabiej wykształconych z krajów rozwijających się, którzy dotychczas wcale nie mieli z nimi styczności. Poza łatwością obsługi ważne jest też to, jak ludzie odbierają możliwość komunikacji werbalnej z urządzeniem - jak pokazało badanie firmy Google z 2017 roku 41% użytkowników inteligentnych głośników stwierdziło, że wydając im komendy głosowe, odnoszą wrażenie, że rozmawiają z człowiekiem.
Interakcja naturalna i nieabsorbująca

(Smart Audio Report Spring 2020)
O tym, że postrzegają te urządzenia jako coś więcej niż elektroniczne zabawki świadczy to, że zwracając się do nich używają takich zwrotów, jak "proszę", "dziękuję", "przepraszam". 53% ankietowanych przez Google stwierdziło, że "rozmowa" z inteligentnym głośnikiem jest dla nich naturalna. Ponadto prawie 70% zapytań do Asystenta Google jest wyrażanych w języku naturalnym, a nie w typowych słowach kluczowych wpisywanych podczas wyszukiwania w przeglądarce internetowej. Wprowadzenie nowego modelu interakcji człowiek-technologia to jednak nie wszystko. Poza tym sterowanie głosowe, nie wymagając angażowania rąk ani oczu, nie przeszkadza w innych jednocześnie wykonywanych czynnościach, na przykład pozwala się skupić na prowadzeniu samochodu. Prawdopodobnie dlatego najwięcej (10%) osób niebędących jeszcze użytkownikami technologii głosowych byłoby zainteresowanych możliwością skorzystania z nich właśnie w aucie, na równi (także 10% ankietowanych) z taką opcją w telefonie, jak wynika z raportu Smart Audio Report Spring 2020. Sterowanie głosowe jest też mniej uciążliwe, inaczej niż w przypadku ekranów, których użytkownicy zwykle uskarżają się na zmęczenie oczu.
Wady i ograniczenia sterowania głosowego
Jak z kolei wykazał raport Smart Audio Report Spring 2020 dla osób, które nie zdecydowały się jeszcze na zakup inteligentnego głośnika sterowanego głosowo, największym problemem jest to, że takie urządzenia ciągłe nasłuchują, oczekując na skierowaną do nich komendę głosową. Obawę taką wyraziło 66% ankietowanych. 65% martwi się z kolei, że hakerzy mogą używać inteligentnych głośników, aby uzyskać dostęp do ich domu lub danych osobowych. 58% nie ufa firmom odpowiadającym za bezpieczeństwo danych, do których dostęp mają inteligentne głośniki. Ciekawostką jest, że aż 46% obawia się, że za ich pośrednictwem rząd będzie mógł podsłuchiwać ich prywatne rozmowy. Wśród ograniczeń sterowania głosowego wymienia się także problemy z interpretacją wypowiedzi użytkownika. Na pytanie: jak często głośnik nie rozumie lub nie słyszy twoich komend, 11% respondentów odpowiedziało, że kilka razy w ciągu dnia, 22% - co najmniej raz dziennie, 30% - przynajmniej raz w tygodniu. Z drugiej strony jednak 65% ankietowanych przyznało, że technologia asystentów głosowych została ostatnio ulepszona. Ponadto korzystanie z urządzeń sterowanych głosowo jest wciąż problemem w przestrzeni publicznej, ze względu na kwestie prywatności i hałas utrudniający komunikację.
Jaką rolę sterowaniu głosem odegrała chmura?
Technologie głosowe nie są nowym rozwiązaniem - pierwsze interfejsy użytkownika tego typu zostały opracowane już ponad trzydzieści lat temu. Niestety, przez wiele lat, ze względu na ich niedoskonałości, głównie małą dokładność i zawodność, i fakt, że ich implementacja wymaga dużych mocy obliczeniowych i zasobów pamięci, nie korzystano z nich na masową skalę.
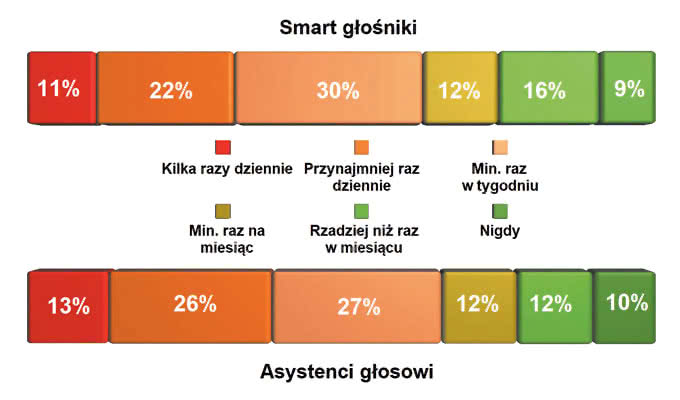
komend? (Smart Audio Report Spring 2020)
Zmieniło się to w ciągu ostatnich kilku lat dzięki postępowi w zakresie przede wszystkim technik sztucznej inteligencji, zwłaszcza uczenia maszynowego, która przestała być naukową ciekawostką, wkraczając "pod strzechy", gdzie znalazła liczne praktyczne zastosowania. To z kolei było możliwe na taką skalę, ponieważ wreszcie dostępna stała się wymagana moc obliczeniowa, którą zapewnił rozwój technologii chmury. Dzięki temu techniki takie, jak głębokie sieci neuronowe czy sieci neuronowe rekurencyjne, odgrywające kluczową rolę w systemach rozpoznawania mowy, można było w końcu efektywnie implementować - moc obliczeniowa zapewniona w chmurze pozwoliła na osiągnięcie dokładności rozpoznawania mowy, mierzonej wskaźnikiem WER (Word Error Rate), sięgającej 95%. Uzyskanie takiego poziomu precyzji okazało się momentem przełomowym - od tej pory możliwe stało się projektowanie aplikacji i urządzeń rozpoznawania mowy na masową skalę. Co więcej, sztuczna inteligencja plus chmura umożliwiły dalszą ewolucję technologii głosowych, teraz bowiem, gdy z bardzo dużą dokładnością można było przetworzyć mowę na tekst, otworzyło się pole do jego interpretacji. Doprowadziło to do rozwinięcia się technik NLP (Natural Language Processing ) i NLU (Natural Language Understanding). Bazują one na obciążającym obliczeniowo oraz pamięciowo uczeniu maszynowym. Dopełnieniem funkcjonalności rozpoznawania mowy oraz zdolności zrozumienia intencji użytkowników jest możliwość odpowiadania im. W tym przypadku sztuczna inteligencja jest wykorzystywana do rozwoju technik DM (Dialog Management).
Ograniczenia chmury
Niestety, wraz z rozwojem i upowszechnianiem się technologii głosowych coraz wyraźniej zaczęto dostrzegać wady chmur. Przede wszystkim jednym z poważniejszych ograniczeniem jest koszt. Przetwarzanie danych głosowych w chmurze jest usługą płatną. W miarę popularyzacji technik przetwarzania mowy zaczęto dostrzegać, że modele biznesowe, w których płaci się za każdym razem, gdy wykorzystywane są zasoby chmury, nie sprawdzają się w przypadkach użycia, gdy niedrogi sprzęt, na przykład urządzenia gospodarstwa domowego czy elektroniki użytkowej, z usług takich korzystają wiele razy w ciągu dnia. Przykładowo, aktywowany głosem ekspres do kawy łączący się z chmurą publiczną, jeżeli jest używany kilka razy dziennie, kosztuje swojego właściciela nawet kilkanaście dolarów rocznie w przeliczeniu na jedno urządzenie.
Kolejna problematyczna kwestia to odczuwalne opóźnienie w transmisji danych z lokalnych aplikacji i urządzeń do chmury i podobnie w kierunku odwrotnym. W niektórych przypadkach może to mieć znaczenie. Jest to parametr krytyczny zwłaszcza w aplikacjach czasu rzeczywistego, których przykładem są gry - dla opinii graczy kluczowe jest, żeby wydając komendy głosowe, nie odczuwali, że są one wykonywane z opóźnieniem. W przeciwnym razie odniosą wrażenie, że nie jest zagwarantowana interakcja, przez co z pewnością producent gry nie zyska nowych klientów.
W związku z tym, że jak pisaliśmy wyżej, użytkownicy ogromną wagę przywiązują do kwestii ochrony swojej prywatności, też pod tym kątem zaczęto sceptycznie oceniać chmury - poziom bezpieczeństwa danych przetwarzanych w chmurze i ich transmisji jest zwykle decydującym czynnikiem przy wyborze dostawcy usług w chmurze. Na koniec warto dodać, że w związku z rosnącą świadomością potrzeby ograniczania negatywnego wpływu na środowisko zaczęto analizować pod kątem energochłonności również centra danych, które obsługują chmury, zużywając przy tym ogromne ilości energii na chłodzenie urządzeń gwarantujących obliczeniową i pamięciową moc wymaganą przez ich użytkowników.
Przetwarzanie brzegowe
Wszystko to sprawiło, że zaczęto poszukiwać alternatywy dla chmur, która będzie w stanie potrzeby technologii głosowych zaspokoić równie efektywnie, a jednocześnie bez wyżej przedstawionych ograniczeń. Uwaga w pewnym momencie skupiła się na urządzeniach docelowych, głównie tych mobilnych, noszonych i innych, których moce obliczeniowe i pojemności pamięci są coraz większe. Są one obecnie w kręgu zainteresowania w związku z rozwojem Internetu Rzeczy - szacuje się, że urządzenia podłączone do globalnej sieci będą już wkrótce liczone w dziesiątkach miliardów sztuk, a ze względu na ich specyfikę (małe rozmiary, przenośność, brak ekranu dotykowego, zasilanie bateryjne) interfejs głosowy może się okazać jedyną możliwą do realizacji metodą interakcji z nimi.
W obliczu spodziewanego tempa popularyzacji Internetu Rzeczy nieopłacalność korzystania z usług w chmurze stała się jeszcze wyraźniejsza - biorąc pod uwagę to, że zasoby obliczeniowe nie są bezpłatne, warunkiem koniecznym dla upowszechnienia interfejsów głosowych okazało się obniżenie ich kosztów. Kiedy to sobie uświadomiono, zaczęto się zastanawiać, czy nie można by tego samego efektu uzyskać bezpłatnie, dzięki zasobom urządzenia docelowego.
Takie rozważania doprowadziły do wniosku, że zamiast korzystać z usług w chmurze, lepiej obróbkę oraz przechowywanie danych zrealizować lokalnie, w ramach tzw. przetwarzania brzegowego (edge computing). Aby wysoce obciążające algorytmy sztucznej inteligencji można było implementować "na miejscu", w urządzeniach o mimo wszystko zwykle relatywnie niedużych zasobach obliczeniowo-pamięciowych, a w urządzeniach Internetu Rzeczy, jak m.in. elektronika noszona, czy drobniejszy sprzęt AGD, często wręcz szczątkowych, potrzebne są nowe rozwiązania, zarówno sprzętowe, jak i programowe.
Sprzętowo-programowa ofensywa
Od strony sprzętowej wprowadzono szereg nowych, efektywnych platform ze specjalistyczną architekturą zoptymalizowaną pod kątem przetwarzania i akceleracji algorytmów sztucznej inteligencji. Liderami w tym zakresie są firmy technologiczne, głównie Google i Intel, choć niedawno do tego grona dołączył również Microsoft . Oferowane są poza tym procesory aplikacji zoptymalizowane pod kątem ograniczenia zużycia energii, a zatem do urządzeń zasilanych bateryjnie.
Opracowywane są też modele uczenia maszynowego przetwarzające mowę na tekst, które można uruchomić na "małym" procesorze, takim jak na przykład rdzeń ARM11 w Raspberry Pi Zero. Zwykle są w stanie rozróżnić około kilkuset tysięcy słów w danym języku, pod względem wskaźnika WER nie ustępując jednak asystentom głosowym, działającym w chmurze.
Uzupełnieniem mechanizmów zamiany mowy na tekst są algorytmy rozpoznawania słów kluczowych wykorzystujące na przykład uczenie transferowe, które szybko i tanio można dostosować do reagowania na dowolne słowo wybudzające urządzenie sterowane głosowo i algorytmy interpretacji prostych poleceń z ograniczonego zbioru. Jeżeli ten ostatni jest ściśle zdefiniowany, a użytkownicy będą wydawać polecenia tylko z tego zestawu, wykorzystując uproszczone algorytmy NLU, można zaprojektować bardzo obliczeniowo oraz pamięciowo wydajny model uczenia maszynowego. Ten będzie można przeszkolić zależnie od aplikacji - przykładowo model obsługujący sterowaną głosowo lodówkę będzie trenowany na innym zestawie danych, niż model do ekspresu do kawy z interfejsem głosowym. Po zaprogramowaniu mikrokontrolerów obu urządzeń ich producenci będą ponosić ewentualnie jedynie opłaty licencyjne na rzecz twórcy modelu.
Podsumowanie
Aby możliwe było uruchamianie modeli przetwarzania języka naturalnego na procesorach o małych zasobach obliczeniowo-pamięciowych, projektanci opracowują nowe sposoby uczenia modeli, które sprawiają, że zajmują one mniej miejsca w pamięci oraz są wydajniejsze obliczeniowo. W jednym z podejść analizowane są zestawy instrukcji danego mikroprocesora oraz operacje matematyczne, które można wydajnie zaimplementować, dysonując takim zbiorem komend. Przykładowo za pomocą innych operacji matematycznych, wydajniejszych do realizacji przy użyciu instrukcji dostępnych w danym procesorze, odwzorowywane jest mnożenie macierzy. Dzięki temu wytrenowane modele są zoptymalizowane pod kątem zasobów konkretnego urządzenia docelowego.
Podsumowując, to, czy głos w końcu stanie się domyślnym interfejsem, użytkownika w elektronice użytkowej jest już prawdopodobnie przesądzone. Umożliwi to połączenie zaawansowanych, wydajnych algorytmów sterowania głosem opartych na sztucznej inteligencji, środowisk programistycznych, które umożliwiają ich implementację programową i rosnącego asortymentu energooszczędnych i ekonomicznych rozwiązań sprzętowych, które umożliwiają ich wdrożenie. Jeżeli jednak chodzi o samo przetwarzanie brzegowe, eksperci są bardziej sceptyczni - zdaniem wielu jest mało prawdopodobne, aby całkowicie zastąpiło w tym zastosowaniu chmurę. Raczej zapewni nową jakość, przy czym chmura będzie nadal wykorzystywana, gdy tylko to będzie możliwe, aby wspierać rozwijający się Internet Rzeczy.
Monika Jaworowska














