
Żyjemy w ekscytujących czasach, w których sztuczna inteligencja rewolucjonizuje codzienne życie, a narzędzia takie jak ChatGPT na nowo definiują produktywność. Wraz z rozwojem systemów opartych na sztucznej inteligencji tradycyjne modele biznesowe i założenia są podważane.
Jaka jest zatem rola głosu w rozwijającym się środowisku sztucznej inteligencji? Czy my, jako liderzy biznesu, musimy zrewidować nasze podejście? Czy rozwój generatywnej sztucznej inteligencji zmniejszy znaczenie dźwięku wysokiej jakości, czy też stanie się on niezbędny dla powszechnego stosowania usług opartych na AI i asystentów osobistych?
AI - od asystenta do przyjaciela
Ludzie naturalnie dostosowują swoje odpowiedzi nie tylko do treści pytania, ale także do kontekstu i formy, w jakiej zostało ono zadane. Ludzki głos dostarcza różnorodnych sygnałów, które można wykorzystać do określenia wieku, płci, pochodzenia społecznego i kulturowego oraz stanu emocjonalnego osoby zadającej pytanie. Ponadto rozpoznanie otoczenia (np. lotniska, biura, transportu lub aktywności fizycznej, takiej jak bieganie) może pomóc w określeniu intencji osoby zadającej pytanie i odpowiednim dostosowaniu odpowiedzi.
Pomimo znacznego postępu w zakresie możliwości sztucznej inteligencji, nadal panuje przekonanie, że wspomaganie oparte na sztucznej inteligencji nie jest w stanie prawidłowo przewidzieć intencji pytania zadanego przez człowieka ani interpretacji konkretnej wiadomości. Aby usprawnić interakcję człowiek-maszyna, w decyzjach retorycznych podejmowanych przez sztuczną inteligencję należy uwzględnić trzy kluczowe czynniki: znajomość słuchacza, jego stan emocjonalny oraz kontekst środowiskowy.
W wielu przypadkach sam odebrany sygnał audio wystarcza do wydobycia użytecznych informacji i dostosowania odpowiedniej reakcji. Rozważmy na przykład rozmowę telefoniczną lub audiokonferencję z osobami, których nigdy nie spotkaliśmy. Co ważniejsze, zastanówmy się, jak postrzeganie innej osoby ewoluuje i zmienia się po wielokrotnych rozmowach, bez możliwości bezpośredniej interakcji.
Niedawne badania sugerują, że nawet niewielkie zmiany w stylu językowym odpowiedzi sztucznej inteligencji powodują zauważalną zmianę w postrzeganiu jej kompetencji społecznych i osobowości. Można zasadnie postawić hipotezę, że przy odpowiednim poziomie bodźców akustycznych przyszłe systemy AI będą w stanie funkcjonować jako skuteczni towarzysze, wykazując zachowania typowe dla ludzkiego przyjaciela, takie jak dociekliwość i szczere słuchanie odpowiedzi lub po prostu słuchanie i powstrzymywanie się od osądzania.
Jak ludzie odbierają sygnały głosowe?
Jak w przypadku każdej komunikacji werbalnej, komunikat audio wykorzystuje język i słowa do przekazywania myśli, uczuć i idei. Ponadto inne elementy komunikacji, takie jak wysokość dźwięku, prędkość wypowiedzi, głośność i hałas otoczenia, mogą wpływać na ogólny odbiór komunikatów.
Z naukowego punktu widzenia ludzkie ucho jest zdolne do odbierania sygnałów dźwiękowych na podstawie dwóch czynników: częstotliwości i poziomu ciśnienia akustycznego. Poziom ciśnienia akustycznego (SPL) jest określany w decybelach (dBSPL), co wskazuje amplitudę ciśnienia akustycznego oscylującego wokół ciśnienia atmosferycznego otoczenia. Poziom SPL wynoszący 100 dBSPL jest porównywalny z bardzo głośnym hałasem kosiarki do trawy lub lecącego helikoptera.
Najniższy punkt w zakresie SPL (0 dB) jest związany z oscylacją ciśnienia akustycznego wynoszącą 20 μPa, co odpowiada progowi słyszalności przy częstotliwości 1 kHz dla młodej, zdrowej osoby. Wszystkie dźwięki mowy ludzkiej mieszczą się w paśmie częstotliwości 100 Hz i 8 kHz. Odpowiedni próg słyszalności człowieka, zgodnie z normą ISO 226:2023, przedstawiono na rysunku 1.
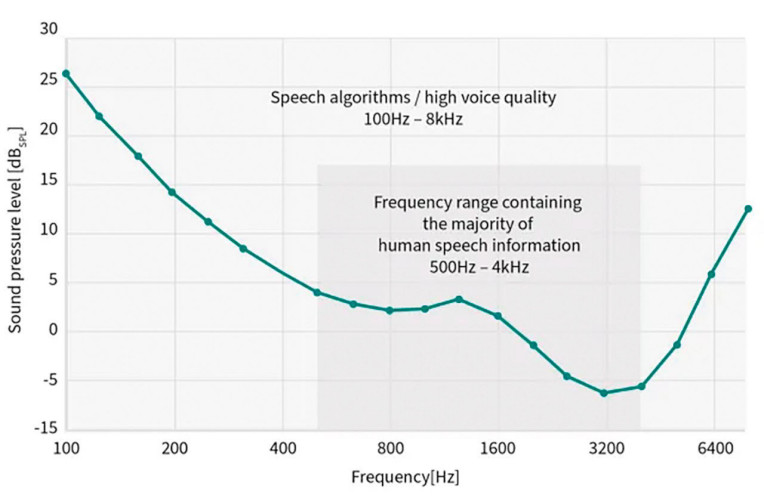
Zwłaszcza częstotliwości z zakresu około 2 kHz mają szczególne znaczenie, a pasmo od 5 kHz do 10 kHz są istotne dla muzyki. Częstotliwości te dodają dźwiękowi "życia" i "jasności". Jednak częstotliwości te zawierają stosunkowo niewiele informacji dotyczących mowy, jedynie sybilanty, czyli syczący dźwięk na początku słów takich jak "statek", "chip" i "zip". Zmniejszenie sybilanty do około 6–8 kHz może mieć szkodliwy wpływ na zrozumiałość mowy.
Jak większość z nas wie, próg słyszalności człowieka obniża się z wiekiem, jak pokazano na rysunku 2.
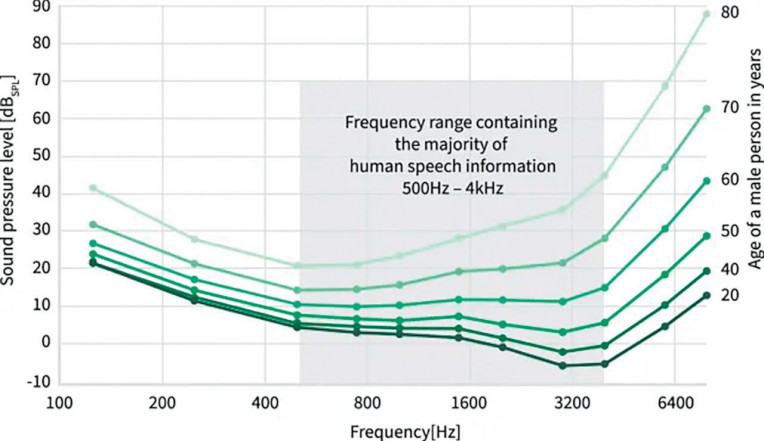
Należy zauważyć, że nawet łagodna utrata słuchu, której doświadcza większość osób w wieku od 40 do 50 lat, może mieć znaczący wpływ na życie jednostki. Na przykład osoba z łagodną utratą słuchu może mieć trudności ze śledzeniem rozmowy grupowej w hałaśliwym otoczeniu. Ponadto może nie słyszeć ważnych sygnałów dźwiękowych, takich jak sygnały ostrzegawcze lub alarmy.
Czy obecny na rynku sprzęt audio jest wystarczający dla przyszłych zastosowań AI?
Teraz, gdy lepiej rozumiemy, jak ludzie odbierają sygnały audio, powróćmy do pierwotnego pytania dotyczącego jakości sygnału wejściowego audio niezbędnej, aby obecna i przyszła sztuczna inteligencja działała na poziomie nieodróżnialnym dla człowieka.
Podobnie jak w przypadku większości urządzeń konsumenckich dostępnych obecnie na rynku, sygnały audio są rejestrowane za pomocą mikrofonów MEMS. Mikrofony takie to także podstawowy komponent do przechwytywania dźwięku dla asystentów osobistych opartych na AI.
Jakość nagrań audio generowanych przez mikrofon MEMS zależy od jego zakresu dynamicznego. Górna granica zakresu dynamicznego jest definiowana przez punkt przeciążenia akustycznego (AOP), który definiuje zniekształcenia mikrofonu przy wysokich poziomach ciśnienia akustycznego (SPL). Z kolei szum własny mikrofonu ogranicza jego zakres dynamiczny w dolnym końcu spektrum.
Tradycyjną miarą szumu własnego mikrofonu jest stosunek sygnału do szumu (SNR), który określa stosunek szumu własnego mikrofonu do pożądanego sygnału, który jest rejestrowany. Jednak wartość SNR może być nieco myląca na potrzeby naszej dyskusji, ponieważ jej definicja sugeruje, w jaki sposób ludzie odbierają sygnał audio, korzystając z krzywej korekcji A.
Jeśli docelowym odbiorcą zarejestrowanego sygnału jest sztuczna inteligencja, bardziej odpowiednim sposobem określenia wydajności mikrofonu jest parametr zwany równoważnym poziomem szumu (ENL), który ignoruje charakterystykę percepcji dźwięku przez człowieka. ENL odnosi się do sygnału generowanego przez mikrofon przy braku zewnętrznego źródła dźwięku i wskazuje poziom ciśnienia akustycznego, który wytworzy takie samo napięcie, jak szum własny mikrofonu.
ENL mikrofonu w całym paśmie częstotliwości można uznać za parametr najbardziej zbliżony do progu słyszalności mikrofonu. Należy zauważyć, że jest to bardzo uproszczone założenie, ponieważ w torze audio zazwyczaj występuje wiele innych komponentów, w tym kanał dźwiękowy, elementy ochrony przed wodą i tor przetwarzania dźwięku z sensora.
Na rysunku 3 przedstawiono graficzną reprezentację krzywych ENL dwóch mikrofonów MEMS w porównaniu z progiem słyszalności człowieka.
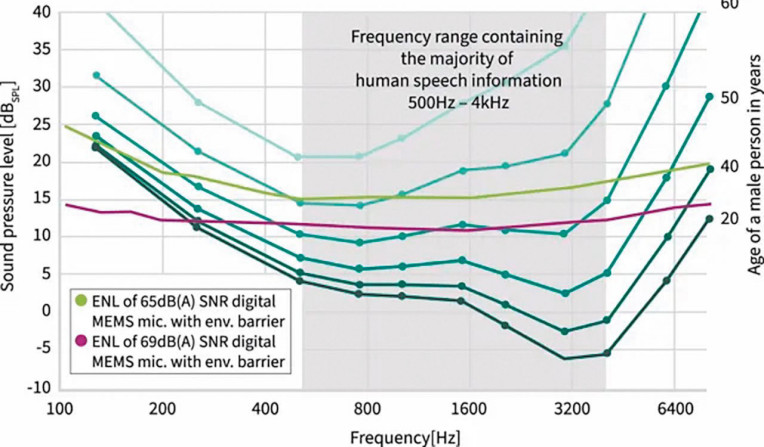
Zielona linia przedstawia krzywą ENL mikrofonu o współczynniku SNR 65 dB(A) z wbudowaną ochroną środowiskową chroniącą przed kurzem. Taki mikrofon MEMS jest obecnie używany w kilku smartfonach wysokiej klasy różnych producentów.
Fioletowa linia poniżej przedstawia krzywą ENL dla najnowszego mikrofonu cyfrowego wysokiej klasy firmy Infineon, który ma innowacyjną barierę środowiskową chroniącą przed cząstkami stałymi i wilgocią. Mikrofon ten reprezentuje najnowszy stan techniki i został wprowadzony na rynek dopiero w tym roku w wysokiej klasy tablecie. Przewidujemy, że mikrofony o porównywalnej wydajności będą dostępne w zaawansowanych smartfonach do końca 2025 roku. Warto zauważyć, że obniżenie szumu własnego mikrofonu o 5 do 10 dBSPL stanowi znaczące osiągnięcie, szczególnie biorąc pod uwagę logarytmiczną skalę ciśnienia akustycznego.
Chociaż firma Infineon poczyniła znaczne postępy w redukcji szumu własnego mikrofonów MEMS, nadal istnieje znaczna luka w zdolności mikrofonu do rozróżniania niskich poziomów ciśnienia akustycznego w porównaniu z ludzkim uchem.
W szczególności pasmo 2 kHz ma kluczowe znaczenie dla zapewnienia dużego poziomu zrozumiałości dźwięku dla słuchaczy. Różnica między słuchem młodej osoby a możliwościami najnowocześniejszego mikrofonu Infineon wynosi ponad 12 dBSPL.
W porównaniu z mikrofonami stosowanymi obecnie w zaawansowanych smartfonach różnica ta jest znacznie większa i wynosi 17 dBSPL. Należy ponownie zaznaczyć, że niniejsza ocena uwzględnia jedynie szum własny mikrofonu MEMS i nie uwzględnia dodatkowych źródeł szumu w torze audio, co dodatkowo obniża ogólną wydajność.
Obecne ograniczenia technologii mikrofonów MEMS są najbardziej widoczne w zakresie częstotliwości, w którym znajduje się większość informacji o ludzkiej mowie (500 Hz – 4 kHz). Nawet najbardziej zaawansowane mikrofony MEMS dostępne na rynku są w stanie odbierać dźwięk jedynie na poziomie porównywalnym z poziomem słuchu 60-latka.
Na podstawie dostępnych danych można zasadnie oczekiwać, że wirtualni asystenci bazujący na sztucznej inteligencji, korzystający z najnowszej technologii mikrofonów MEMS, będą doświadczać ubytków słuchu podobnych do tych, jakie mają osoby starsze, szczególnie w sytuacjach, gdy muszą śledzić rozmowy w hałaśliwym otoczeniu lub z dużej odległości.

Podsumowanie
Szybki postęp w dziedzinie sztucznej inteligencji (AI) nie spowolni, a wręcz przyspieszy rozwój technologii mikrofonów MEMS o wyższym współczynniku SNR. Chociaż najnowsze sensory nie dorównują jeszcze jakością dźwięku równoważą moliwościom ludzkiego ucha, postęp w redukcji szumu własnego przyniesie korzyści rozwiązaniom AI.
Dalsze udoskonalanie toru audio będzie kluczowe dla zwiększenia możliwości sztucznej inteligencji, takich jak klasyfikacja środowiskowa, rozumienie kontekstu, świadomość emocjonalna, identyfikacja mówcy i identyfikacji i oznaczania różnych wielu mówców w rozmowie. Dzięki lepszemu sygnałowi audio AI będzie w stanie komunikować się z ludźmi w sposób, który dorównuje najlepszym zachowaniom człowieka.
Ponadto, wyższy poziom interakcji człowiek-maszyna umożliwi nowe zastosowania i usługi oparte na AI. Wyobraźmy sobie na przykład przyszłą wersję Copilota firmy Microsoft, która nie tylko podsumowuje spotkanie w Teams, ale także zapewnia ogólną ocenę nastroju rozmowy.
Przyszła AI może być w stanie podkreślać lub oceniać znaczenie omawianych działań, opierając się wyłącznie na ludzkiej mowie i dźwięku. Istnieje również możliwość dodania funkcji coachingowych opartych na sztucznej inteligencji, które zapewnią użytkownikowi przydatne porady na temat tego, jak lepiej kierować przyszłymi rozmowami w pożądaną stronę.
Wyobraź sobie oparte na sztucznej inteligencji rozmowy kwalifikacyjne z nowymi kandydatami na pierwszym etapie lub możliwość identyfikacji rozmówców na podstawie samego dźwięku, z poziomem bezpieczeństwa wystarczającym do zakupów online.
To wszystko prawdopodobnie tylko niewielki przykład tego, czego można oczekiwać od przyszłych systemów z możliwościami słyszenia dorównującymi lub przewyższającymi ludzkie.
Infineon
https://www.infineon.com/microphones
















