
Do takich zadań potrzebne są mikrofony o znakomitych parametrach jakościowych zapewniające zoptymalizowane przechwytywanie sygnałów dźwiękowych i głosowych w różnych urządzeniach. Konstruując urządzenia z mikrofonami, warto zwrócić uwagę na rodzinę takich produktów XENSIV firmy Infineon. Są one wykonane w technologii MEMS i ich cechą charakterystyczną jest to, że pokonują one obecne ograniczenia przy rejestracji sygnału audio.
Wersje MEMS w porównaniu do klasycznych rozwiązań pojemnościowych i elektretowych mają wiele zalet. Po pierwsze są one znacznie mniejsze przy takiej samej wydajności, dzięki czemu można je łatwiej integrować wewnątrz urządzeń oraz wykorzystywać wiele mikrofonów rozmieszczonych w różnych miejscach toru akustycznego, bez martwienia się o zajętość miejsca.
Po drugie, proces produkcyjny takich elementów pozwala na fabryczne trymowanie parametrów, przez co można traktować je jako elementy parowane z jednakową charakterystyką amplitudową i fazową. Dzięki temu upraszcza się konstrukcja aplikacji, bo nie jest wymagane precyzyjne strojenie każdej sztuki. Kolejna korzyść to odporność na wysokie temperatury i możliwość montażu automatycznego w procesie SMT.
Parametry mikrofonów o wysokiej wydajności
Jako przetwornik dźwięku mikrofon przekształca fale ciśnienia dźwięku w sygnały elektryczne. Jednak nie wszystkie mikrofony są jednakowe - są one charakteryzowane przez różne parametry, które razem określają, czy dany element nadaje się do konkretnej aplikacji. Poniżej zostaną scharakteryzowane te najważniejsze.
Poziom szumów w sygnale wyjściowym mikrofonu odnosi się do wszystkich sygnałów, które nie pochodzą z pożądanego sygnału wejściowego. Szum może występować w otoczeniu lub pochodzić z samego mikrofonu, a im wyższy poziom szumów, tym gorsza jakość zarejestrowanego sygnału audio.
Różne parametry lub specyfikacje określają poziom szumu w mikrofonach. Z jednej strony szum własny - generowany przez sam mikrofon, gdy nie ma sygnału dźwiękowego. Mierzy się to w Vrms, dBV lub dBFS. Ekwiwalentny szum wejściowy to z kolei wyimaginowany poziom szumu akustycznego, który odpowiada poziomowi szumu elektrycznego na wyjściu mikrofonu.
Wyraża się go w dB SPL (poziom ciśnienia akustycznego dB). Ważnym kryterium jest stosunek sygnału do szumu (SNR). Wartość SNR wyrażona w dB jest miarą szumu własnego mikrofonu w stosunku do zamierzonego lub pożądanego sygnału wejściowego.
Inne ważne cechy jakości mikrofonów to całkowite zniekształcenia harmoniczne (THD) i akustyczny punkt przeciążenia (AOP). W rzeczywistości mikrofony, podobnie jak wszystkie konwertery sygnałów, są nieliniowe, tj. wnoszą pewny poziom zniekształceń, tj. dodatkowe harmoniczne zwykle od drugiej do piątej.
THD to stosunek energii zawartej w tych harmonicznych do energii sygnału częstotliwości podstawowej. Jest wyrażony w procentach. Zasadniczo AOP określa punkt, w którym THD przekracza 10%. Jednak w bardziej wymagających aplikacjach AOP jest czasem określany jako punkt, w którym THD=1%. Kolejne parametry to odpowiedź częstotliwościowa i faza.
Właściwości i istotne parametry
Działanie mikrofonu MEMS bazuje na miniaturowym kondensatorze, jaki tworzy membrana będąca jedną z jego okładek oraz płytką tylną - drugą okładką. Między obie te elektrody podawane jest napięcie polaryzacji. Odkształcająca się membrana pod wpływem ciśnienia akustycznego wywołuje zmianę napięcia na okładkach tego kondensatora, co jest wynikiem zmiany pojemności (odległości elektrod) przy stałym ładunku (rys. 1).
Podstawowy układ mikrofonu z dwoma elektrodami, a więc membraną oraz tylną płytką (back plate), można w bardziej złożonym rozwiązaniu zastąpić rozwiązaniem z dwoma płytkami tylnymi. Są one rozmieszczone symetrycznie pod i nad membraną, jak pokazano na rysunku.
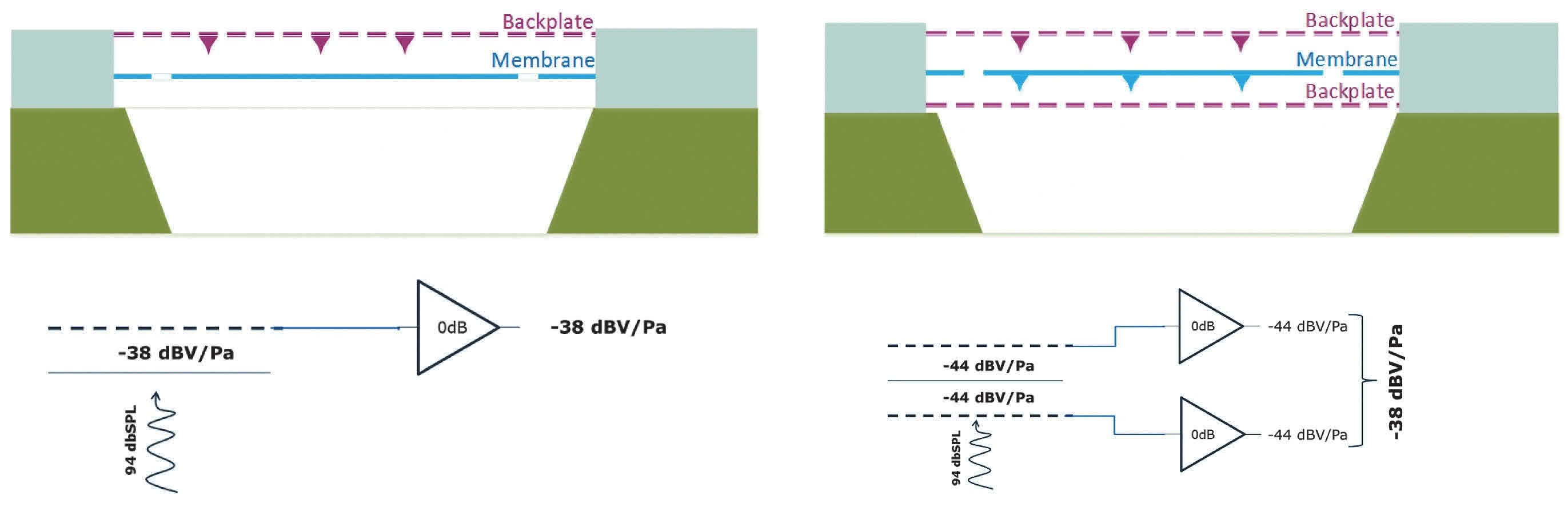
Taka konstrukcja tworzy podwójny kondensator dostarczający sygnału różnicowego. Wymaga on bardziej złożonego wzmacniacza, ale finalnie od strony parametrów takie mikrofony mają lepszą liniowość (a więc niższe zniekształcenia THD) oraz są bardziej odporne na przesterowanie przy bardzo głośnych sygnałach akustycznych. Symetryczna konstrukcja i wzmacniacz różnicowy pomagają też w tłumieniu wybranych harmonicznych (rys. 2).
Mikrofony MEMS mogą mieć wyjście analogowe lub cyfrowe. To pierwsze rozwiązanie jest prostsze, bo do pracy konieczna jest pompa ładunku dostarczającą napięcia polaryzacji dla sensora akustycznego oraz niskoszumowy wzmacniacz. W drugim przypadku konieczny jest jeszcze przetwornik analogowo-cyfrowy z filtrem antyaliasingowym oraz układ interfejsu.
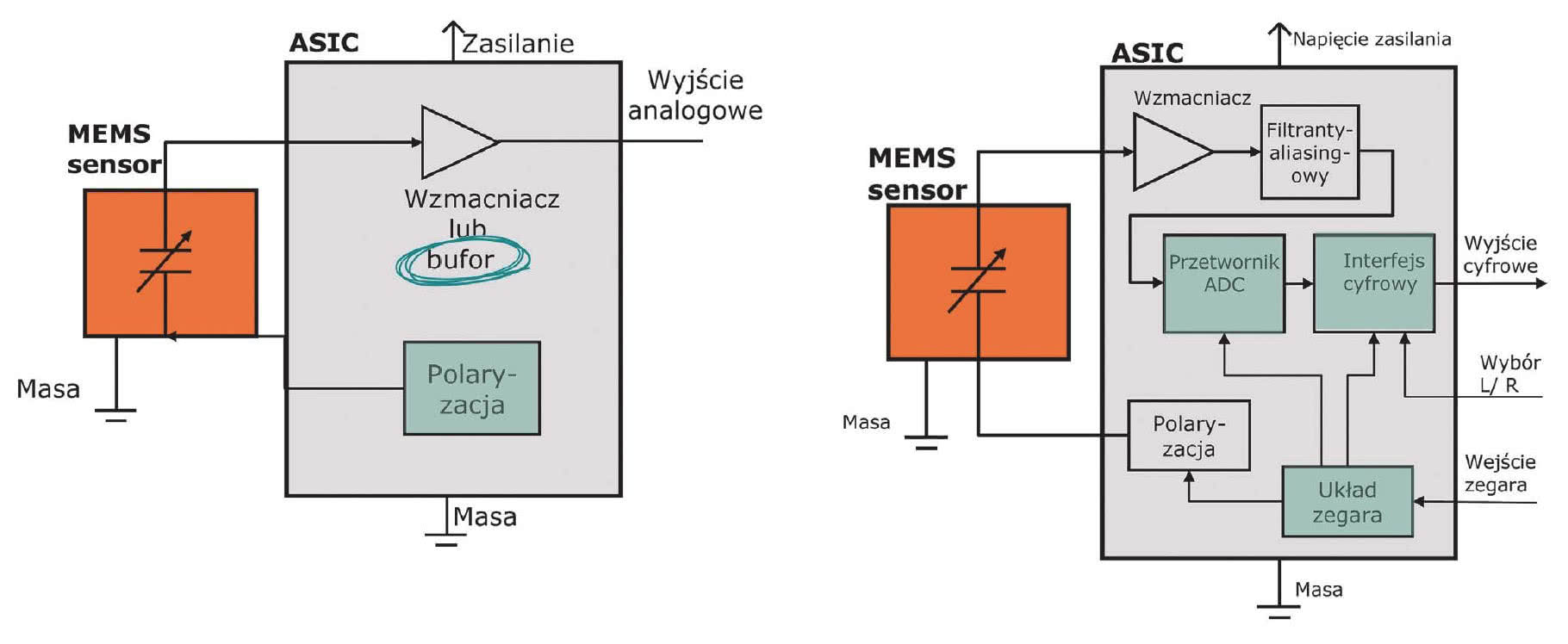
Wyjście cyfrowe zapewnia łatwość połączenia mikrofonu z systemem cyfrowym, np. mikrokontrolerem i ułatwia panowanie nad zakłóceniami. Elementy analogowe są bardziej wymagające, jeśli chodzi o odprzęganie zasilania i wymagają starannego projektu PCB. Ich użycie wymaga więcej miejsca na płytce, natomiast wersje cyfrowe wymagają jedynie pojedynczej pojemności odsprzęgającej zasilanie.
Linia sygnałowa pomiędzy sensorem a przetwornikiem ADC jest w tym przypadku bardzo krótka, zatem podatność na zakłócenia jest znacznie mniejsza. Porównanie funkcjonalności obu tych wersji pokazano w ramce (rys. 3).
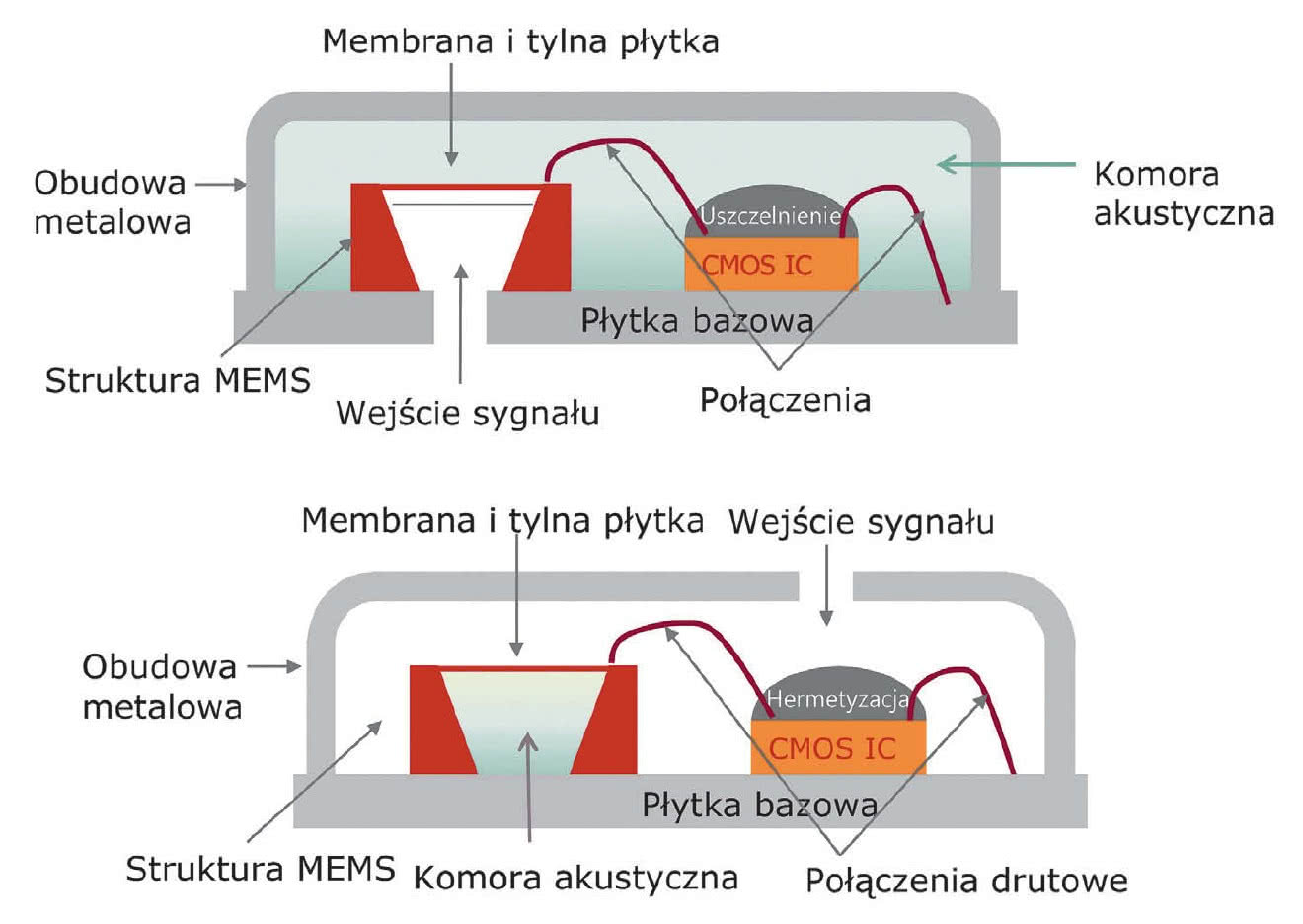
Kolejna różnica pomiędzy mikrofonami to rodzaj wejścia sygnału akustycznego. Dostęp do membrany może być wykonany od spodu lub od góry obudowy, jak pokazano na rysunkach. Wybór wersji zależy od wymagań konstrukcyjnych aplikacji i tego, jak może być wykonany kanał akustyczny doprowadzający dźwięk do membrany.
Ogólnie mikrofony z wejściem dolnym zapewniają lepsze parametry, ale są trudniejsze w aplikacji. To dlatego, że komora akustyczna, w której pracuje sensor, jest tutaj mniejsza i nie ma w niej innych elementów poza membraną, które zakłócają pracę, np. tworząc pasożytnicze rezonanse. Mikrofony z dolnym wejściem wykorzystywane są w bardziej zaawansowanych aplikacjach, w tym smartfonach. Te drugie wybierane są do mniej wymagających zastosowań, np. w laptopach. Są też czulsze od równoważnych wersji z wejściem dolnym (rys. 4).
Czułość i tolerancja
Jednym z podstawowych parametrów mikrofonu jest czułość, ale ponieważ coraz więcej urządzeń zawiera więcej niż jeden taki element, równie ważne staje się to, aby wszystkie elementy miały taką samą czułość, jednakową charakterystykę fazową oraz opóźnienie grupowe. Bez tego formowanie wiązki, tłumienie echa oraz aktywna redukcja szumów nie będą działać dobrze.
Mikrofon MEMS XENSIV a klasyczny elektretowyMikrofon XENSIV
Mikrofon elektretowy
|
Zoptymalizowane rozpoznawanie mowy

W przypadku systemów elektronicznych współpracujących z algorytmami komputerowymi (np. do rozpoznawania mowy) sygnały dźwiękowe są odbierane inaczej, niż są odbierane przez ludzkie ucho. W związku z tym cele dotyczące jakości dźwięku są różne. Sygnał niekoniecznie musi brzmieć tu naturalnie, o ile jest zoptymalizowany pod kątem zastosowanych algorytmów. Niezależnie od zastosowania ważne jest, aby sygnał był wolny od zakłóceń i szumów.
Automatyczne rozpoznawanie głosu to proces, w którym sygnały głosowe są automatycznie tłumaczone na tekst pisany. Dokładność takiego zadania wynosi obecnie około 95% i jest już bardzo zbliżona do poziomu osiąganego przez słuchaczy. Niemniej ta wartość została dotychczas osiągnięta jedynie w laboratoriach o bardzo korzystnych warunkach środowiskowych.
Systemy sterowania głosem zawsze powinny zapewniać niezawodność rozpoznawania i łatwość obsługi dla użytkownika końcowego. Aby to osiągnąć, projektanci systemu muszą wziąć pod uwagę faktyczne zastosowanie urządzenia w miejscu pracy, na przykład prawdopodobną odległość użytkownika od mikrofonu i oczekiwany poziom szumów i dźwięków tła. Tylko wtedy możliwe jest zaprojektowanie systemu tak, aby osiągnąć najlepszą możliwą skuteczność.
W praktyce sterowanie głosem jest bardzo podatne na zakłócenia akustyczne takie jak szum tła, pogłos, echo oraz są wrażliwe na pozycję mikrofonu w stosunku do rozmówcy. Z tego powodu nie wystarczy mieć dobre oprogramowanie do rozpoznawania głosu. Każdy element systemu powinien zapewniać najlepszą możliwą wydajność, aby nie nastąpiła utrata jakości działania. Zadaniem mikrofonu jest zapewnienie systemowi rozpoznawania głosu najlepszego możliwego sygnału wejściowego, który pomaga analizować treść głosu w przychodzącym dźwięku.
W głośnym środowisku rozpoznawanie głosu może zostać znacznie poprawione, jeśli zastosowany mikrofon ma wysoką liniowość, czyli zapewnia najmniejszy poziom zniekształceń. Z kolei wysoki AOP pomaga zminimalizować zniekształcenia i poprawić tłumienie hałasu i echa. Czasami sam sygnał głosowy nie jest wystarczająco głośny i istnieją inne dźwięki, które powodują zakłócenia. Dzieje się tak na przykład wtedy, gdy głośnik stoi blisko mikrofonu aktywowanego głosem terminalu lub gdy cyfrowy asystent odtwarza głośną muzykę albo podaje informacje głosowe.
Największy możliwy stosunek sygnału do szumu
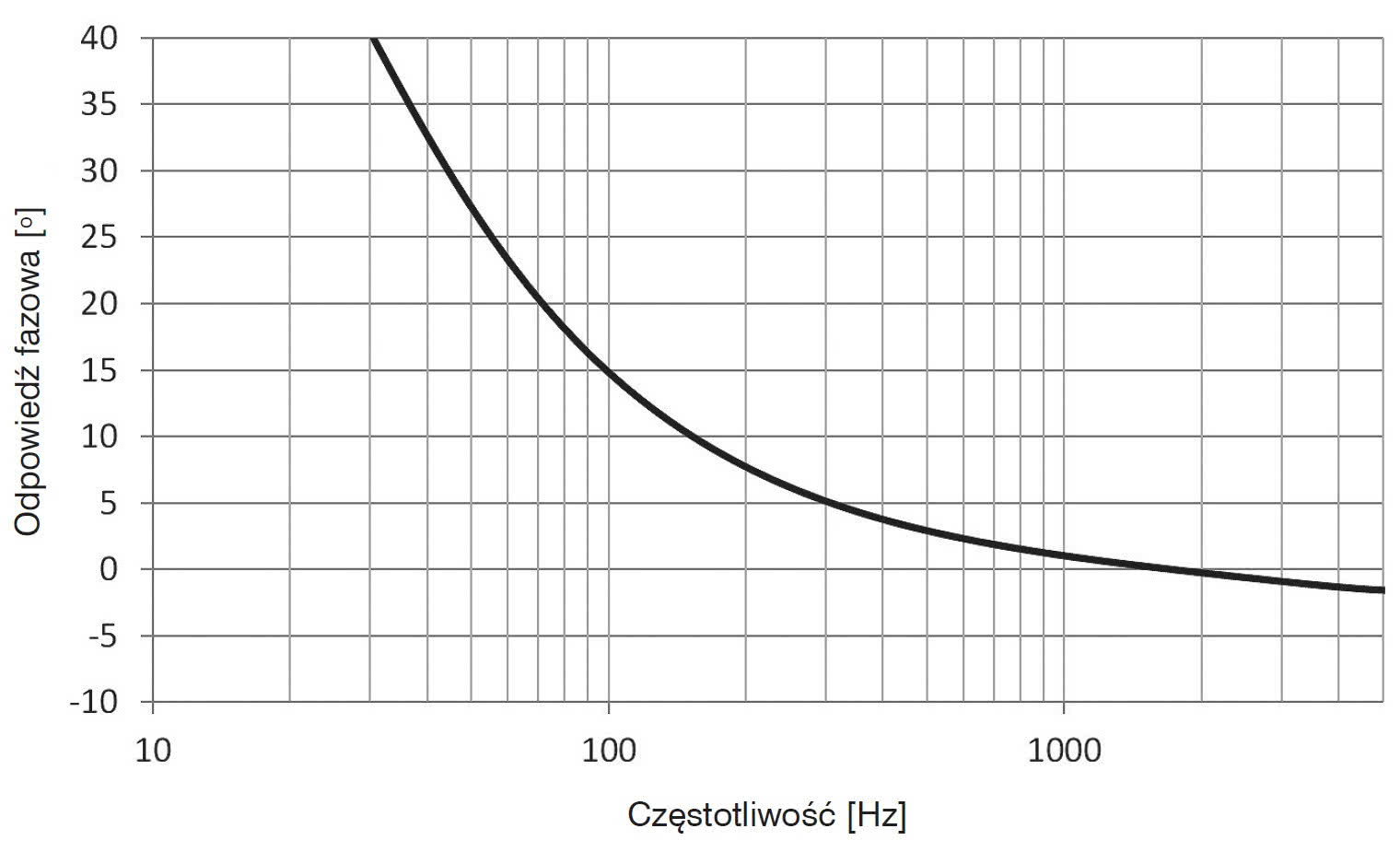
Im większa odległość od źródła sygnału mowy, tym niższy jest stosunek sygnału do szumu sygnału kierowanego do algorytmu. Z tego powodu stosunek sygnału do szumu mikrofonu powinien być wysoki, jeśli zamierzona odległość wykrywania ma być jak największa.
Wykrywanie sygnałów audio, a także jakość rozmów między osobami można poprawić, jeśli niepożądane dźwięki są wymaskowane z sygnału. Celem takiego procesu jest zwiększenie stosunku sygnału do szumu, w tym przypadku stosunku między pożądanym sygnałem dźwiękowym a niepożądanym szumem otoczenia. Redukcję szumów i charakterystykę kierunkową można uzyskać, stosując wiele mikrofonów w połączeniu z odpowiednimi algorytmami, jak jest to w inteligentnych głośnikach, gdzie obok siebie pracuje nawet 7 mikrofonów.
Takie macierze mikrofonów pozwalają na wykorzystanie algorytmów kształtowania wiązki oraz mogą zwiększać czułość mikrofonów w pożądanym kierunku, a więc wzmacniać pożądane źródła dźwięku. Wyrafinowaną metodą tłumienia szumu są algorytmy "separacji ślepego źródła". Umożliwiają one tłumienie hałasu niezależnie od kierunku, odległości i miejsca pochodzenia.
Wszystkie te techniki tłumienia hałasu korzystają z dokładności i jakości odbieranego sygnału. Mikrofon powinien zatem mieć największy możliwy stosunek sygnału do szumu, niskie zniekształcenia, liniową odpowiedź częstotliwościową (co również poprawia odpowiedź fazową) i małe opóźnienie grupowe.
Najważniejsze cechy IM69D130
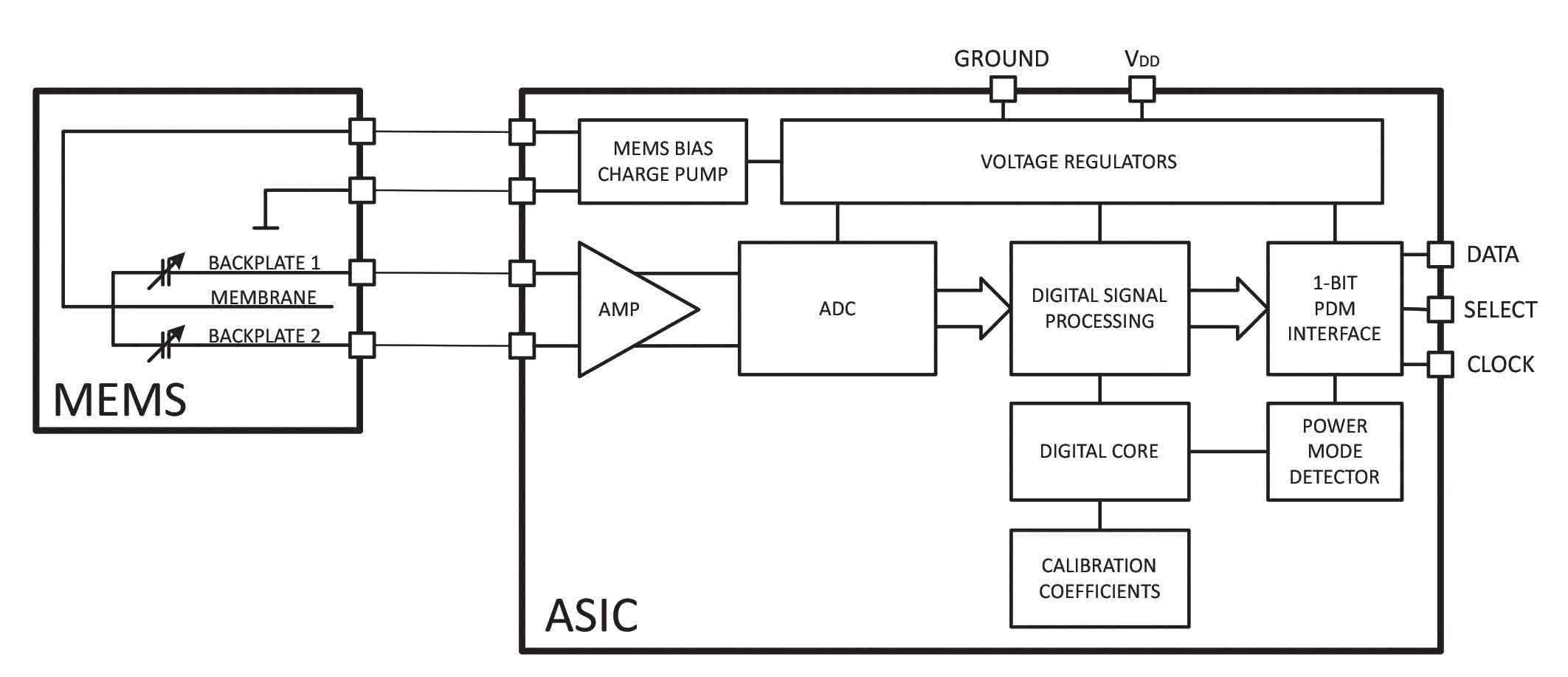
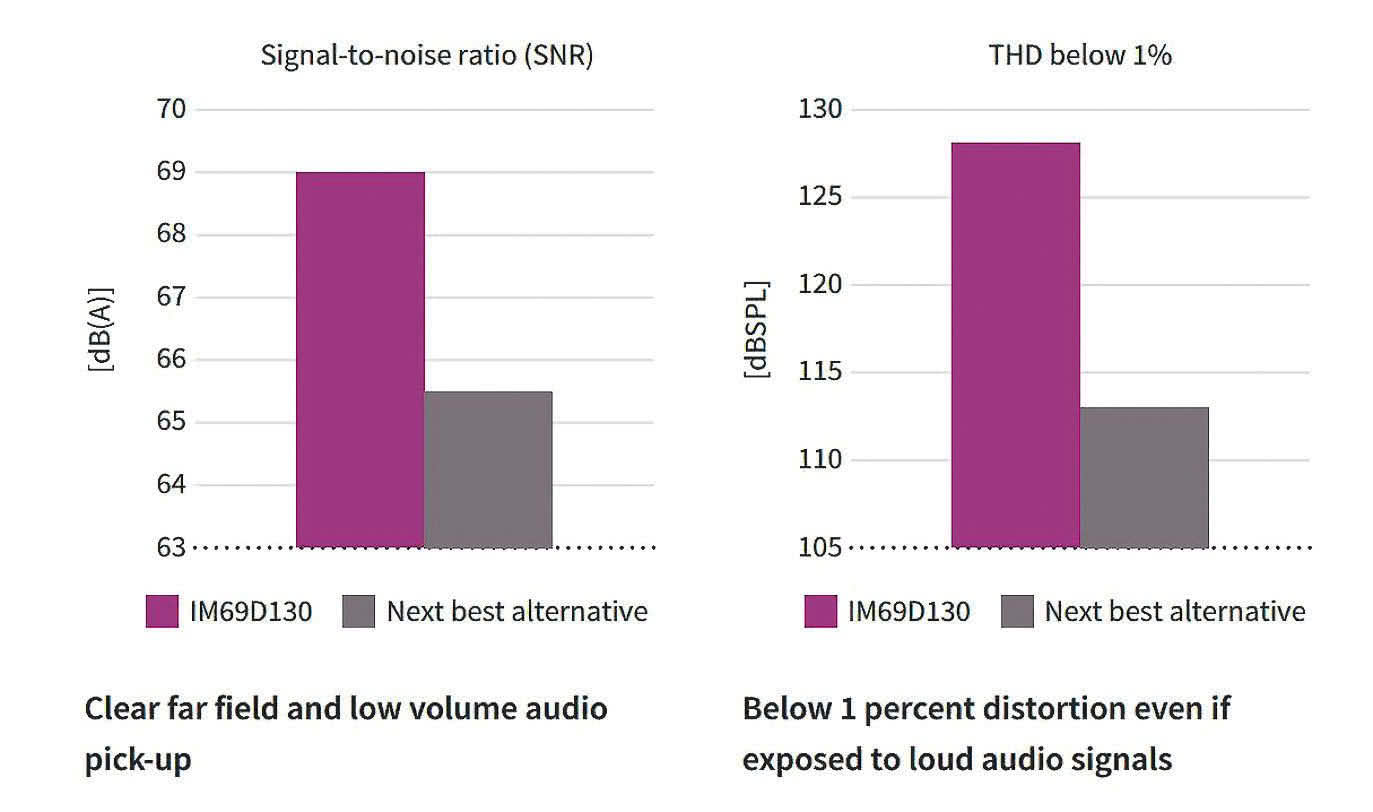
Mikrofon IM69D130 jest przeznaczony do zastosowań, w których wymagany jest wysoki stosunek sygnału do szumu, szeroki zakres dynamiki, niski poziom zniekształceń i wysoka odporność na przeciążenia akustyczne. Pozwala to na przykład na bardzo precyzyjne rozpoznawanie głosu oraz na rejestrację bardzo głośnych dźwięków w aplikacjach scenicznych i przemysłowych. Ma stosunek sygnału do szumu (SNR) wynoszący 69 dB.
Wyposażony jest w podwójną tylną płytę, co zapewnia wysoką liniowość sygnału wyjściowego i zakres dynamiki 105 dB. Szumy własne mikrofonu wynoszą 25 dB (stosunek sygnału do szumu 69 dB), a zniekształcenia nieliniowe nie przekraczają 1% nawet przy poziomie ciśnienia akustycznego wynoszącym 128 dB SPL (10% zniekształceń przy 130 dBSPL).
Oznacza to, że wykrywanie poleceń głosowych bez zniekształceń jest możliwe nawet podczas odtwarzania muzyki z głośników. Liniowa charakterystyka częstotliwościowa (spadek częstotliwości przy niskiej częstotliwości dopiero poniżej 28 Hz) i wąskie tolerancje produkcyjne powodują ścisłe sparowanie fazowe mikrofonów. Element umieszczono w obudowie 4×3×1,2 mm.

Rozrzut czułości wynosi ±1 dB a dopasowanie fazowe ±2° przy 1 kHz. Dzięki temu IM69D130 pozwala na niezwykle dokładne formowanie wiązki audio, umożliwiając współpracę z innowacyjnymi, wydajnymi algorytmami rozpoznawania mowy.
Układ ma na wyjściu interfejs cyfrowy, nie potrzebuje więc dodatkowych komponentów analogowych. Łącze cyfrowe zmniejsza również koszt realizacji, bo nie trzeba chronić linii zasilania przed zaburzeniami wysokiej częstotliwości, a do zastosowań z wieloma mikrofonami potrzeba mniej połączeń.
Zawarty w obudowie układ ASIC zawiera niskoszumowy przedwzmacniacz i wydajny konwerter ADC typu sigma-delta (tylko 6 μs opóźnienia przy 1 kHz). Pozwala on wybrać różne tryby zasilania, aby dostosować je do konkretnych wymagań energetycznych aplikacji. Każdy mikrofon IM69D130 jest fabrycznie trymowany, co zapewnia bardzo małą tolerancję czułości (±1 dB).
W połączeniu z innowacyjnymi algorytmami przetwarzania wysokiej jakości sygnałów danych audio IM69D130 może obsłużyć nawet najbardziej wymagające scenariusze rozpoznawania głosu, takie jak wykrywanie dalekiego pola i wychwytywanie cichych głosów.
Infineon















