
Współczesne systemy embedded zajmują się w przeważającej większości monitorowaniem stanu otoczenia za pomocą zestawu czujników. Postęp w technologii produkcji sensorów, mikroprocesorów oraz rozwój skutecznych protokołów komunikacyjnych umożliwiły masową produkcję układów IoT, zdolnych do tworzenia rozbudowanych sieci połączonych ze sobą urządzeń. Urządzenia te charakteryzują się zazwyczaj przystępną ceną, są zatem produkowane i wykorzystywane w dużej skali, tworząc systemy zarządzające funkcjonowaniem mieszkań, budynków, zakładów produkcyjnych a nawet miast.
Czujniki te monitorują określone wielkości fizyczne w sposób nieprzerwany, generując w związku z tym znaczące ilości danych. Do typowych rodzajów czujników wykorzystywanych w aplikacjach IoT zaliczyć można akcelerometry, żyroskopy, mikrofony, czujniki jakości powietrza, ciśnienia, temperatury, wilgotności czy oświetlenia. Przeważająca większość tych układów wykonana jest w technologii MEMS, stanowiącej filar rozwoju koncepcji IoT.
Algorytmy uczenia maszynowego pozwalają w sposób zautomatyzowany wyszukiwać interesujące wzorce oraz anomalie obecne w zarejestrowanych danych, bez konieczności ich ręcznej analizy. Połączenie koncepcji IoT oraz technik uczenia maszynowego skutkuje powstaniem wielu interesujących rozwiązań oraz urządzeń, oferujących nowe funkcjonalności ich użytkownikom. Standardowe podejście do tego typu zagadnienia obejmowało lokalną rejestrację danych wraz z ich ewentualnym wstępnym przetworzeniem, następnie zaś przesłanie tych informacji do chmury lub lokalnego centrum obliczeniowego, gdzie podlegały one dalszej analizie. W ostatnim czasie coraz większą popularność zdobywa jednak koncepcja tinyML, opierająca się na implementacji algorytmów uczenia maszynowego bezpośrednio w systemach mikroprocesorowych. Rozwiązanie to charakteryzuje się niskim zużyciem energii elektrycznej, krótkim czasem opóźnienia oraz redukcją wymaganego pasma transmisyjnego. Idea ta znajduje zastosowanie m.in. w aplikacjach takich jak inteligentne budynki (smart home), inteligentny przemysł, urządzenia noszone, czy też w branży motoryzacyjnej.
Zalety korzystania z tinyML
Implementacja algorytmów uczenia maszynowego w systemach mikroprocesorowych niesie ze sobą wiele korzyści. Znacząco poprawia bezpieczeństwo aplikacji oraz ochronę prywatności gromadzonych danych. Brak konieczności przesyłania informacji do chmury istotnie utrudnia ich ewentualne przechwycenie oraz odczytanie. Warto pamiętać, że dane rejestrowane przez współczesne urządzenia IoT bardzo często dotyczą informacji wrażliwych i istotnych z punktu widzenia użytkownika, np. zawierających informacje o stanie zdrowia. Z tego powodu bezpieczeństwo i poufność danych jest bardzo ważnym elementem tego typu systemów.

Kolejną zaletą wykorzystania koncepcji tinyML jest znacząca poprawa energooszczędności. Istotne ograniczenie ilości transmitowanych danych zmniejsza zużycie energii elektrycznej, co może przynieść szczególnie zauważalne rezultaty w przypadku układów zasilanych bateryjnie, wydłużając czas pracy układu pomiędzy kolejnymi ładowaniami lub wymianą baterii.
Lokalna implementacja algorytmów uczenia maszynowego skraca też czas opóźnienia pomiędzy zarejestrowaniem a przetworzeniem sygnału. Czas ten wynika jedynie z konieczności przeprowadzenia obliczeń, nie ma zaś związku z parametrami połączenia sieciowego, jak w przypadku rozwiązań chmurowych. Poprawia to szybkość reakcji układów i zwiększa dostępność i niezawodność urządzeń – ewentualne awarie sieci nie mają już wpływu na funkcjonowanie układu i proces przetwarzania sygnału.
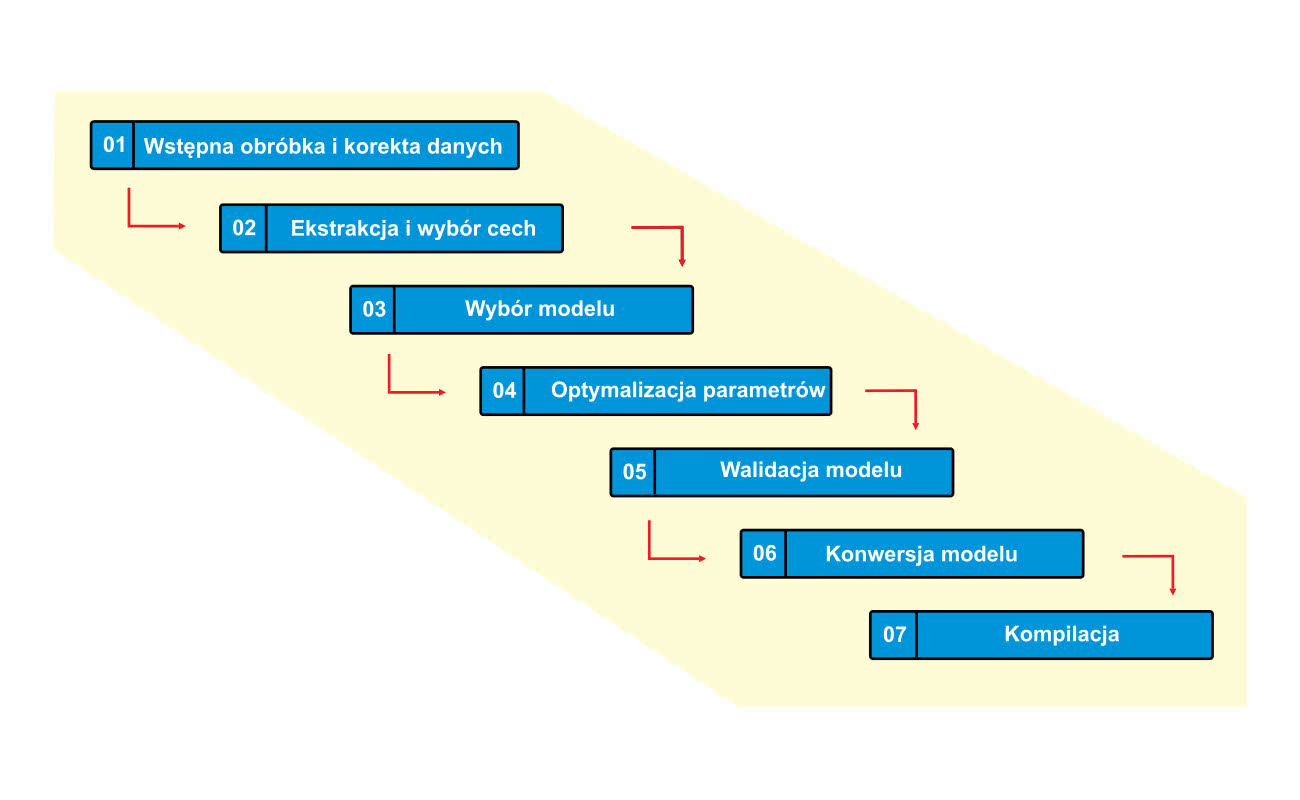
Na rysunku 1 przedstawiono typowe etapy procesu przygotowywania algorytmu uczenia maszynowego. Przed rozpoczęciem tego procesu konieczna jest konfiguracja czujników oraz rejestracja danych treningowych. Dane te można następnie wykorzystać do stworzenia modelu-mechanizmu decyzyjnego, który będzie zaimplementowany w systemie mikroprocesorowym. Istnieją gotowe środowiska i narzędzia pozwalające na tworzenie tego typu modeli, następnie zaś ich kompilację do postaci zrozumiałej przez mikroprocesor. Do najpopularniejszych zaliczyć można TensorFlow Lite oraz Qeexo AutoML. Oba przeznaczone są dla układów o architekturze z rodziny ARM Cortex M.
Implementacja koncepcji tinyML w układach o architekturze ARM Cortex-M
Mikroprocesory o architekturze ARM Cortex M są powszechnie wykorzystywane w rozwiązaniach IoT. Charakteryzują się bardzo małym zużyciem energii elektrycznej oraz przystępną ceną, dostarczając jednocześnie wystarczającej mocy obliczeniowej (w zależności od wersji, mogą być taktowane zegarem o częstotliwości do 64 MHz).
Efektywna implementacja algorytmów uczenia maszynowego w tego typu układach stanowi jednak pewne wyzwanie, szczególnie w przypadku procesorów z serii ARM Cortex-M0, najtańszych i najbardziej energooszczędnych, lecz jednocześnie cechujących się najuboższym wyposażeniem i najmniejszą mocą obliczeniową.
Do podstawowych kłopotów związanych z efektywną implementacją algorytmów uczenia maszynowego zaliczyć można brak zmiennoprzecinkowej jednostki obliczeniowej. Typowe modele decyzyjne obejmują przeprowadzanie operacji cyfrowego przetwarzania sygnału wymagających obliczeń zmiennoprzecinkowych. Ekstrakcja pewnych cech statystycznych (np. analiza widmowa) sygnału za pomocą jedynie operacji stałoprzecinkowych może być bardzo kłopotliwa i skutkować utratą precyzji, przekładającą się następnie na pogorszenie dokładności działania modelu. Problem stanowić może również mała dostępność pamięci, zarówno operacyjnej, jak i Flash. Przekłada się to na konieczność upraszczania modelu decyzyjnego, może również uniemożliwić analizę dużej liczby parametrów. W przypadku algorytmów opartych na strukturze drzewa decyzyjnego konieczne może być ograniczenie rozmiarów tego drzewa. Redukcje te również mogą spowodować degradację ogólnej dokładności algorytmu. W przypadku niektórych algorytmów sporym utrudnieniem okazać się może mała moc obliczeniowa. Rozwiązania sprawdzające się w przypadku "dużych" procesorów taktowanych sygnałami o częstotliwościach powyżej 1 GHz niekoniecznie dobrze sprawdzą się w przypadku układów taktowanych kilkunasto- lub nawet kilkudziesięciokrotnie wolniejszym zegarem.
Wspomniane czynniki powodują, że algorytmy i metody z powodzeniem wykorzystywane w przypadku "dużych" systemów komputerowych nie zawsze dobrze sprawdzą się w świecie embedded. Z tego powodu dużo bardziej efektywne jest korzystanie z dedykowanych narzędzi i mechanizmów, zoptymalizowanych pod kątem ograniczeń charakterystycznych dla mikroprocesorów.
Podsumowanie
Lokalna implementacja algorytmów uczenia maszynowego, określana jako tinyML, jest niewątpliwie atrakcyjną koncepcją, mogącą znacząco podnieść efektywność wielu systemów IoT. Ograniczenia sprzętowe charakterystyczne dla mikroprocesorów uniemożliwiają jednak lub znacząco utrudniają korzystanie z tych samych narzędzi oraz środowisk, które z powodzeniem używane są w przypadku zwyczajnych systemów komputerowych. Modele decyzyjne przeznaczone dla mikrokontrolerów cechować się muszą znacznie większą prostotą oraz niższymi wymaganiami odnośnie do mocy obliczeniowej, rozmiaru kodu oraz pamięci operacyjnej. Jednym ze sposobów rozwiązania tego problemu jest korzystanie z dedykowanych narzędzi przeznaczonych do projektów embedded. Środowiska te kładą szczególny nacisk na optymalizację i uproszczenie utworzonego modelu decyzyjnego, wspierają również określone architektury sprzętowe, umożliwiając bezpośrednią kompilację modelu do postaci zrozumiałej dla danego typu procesora.
Damian Tomaszewski










