
Przez lata sztuczną inteligencję (Artificial Intelligence, AI) utożsamiano z superkomputerem, który dorównuje, a nawet przewyższa intelektem człowieka i jest w stanie tak jak my wyciągać wnioski i uczyć się na podstawie własnych doświadczeń, co zwykle, w filmach science fiction, wykorzystuje przeciwko ludziom. Tego typu rozwiązanie byłoby sklasyfikowane jako silna sztuczna inteligencja AGI (Artificial General Intelligence) lub superinteligencja ASI (Artificial Superintelligence). Są to dwa z trzech głównych podtypów AI.
Okazuje się jednak, że to wyobrażenie ma jak na razie niewiele wspólnego z rzeczywistością. Choć bowiem prowadzi się prace nad AGI/ASI i z pewnością postęp w tym zakresie byłby fascynującym osiągnięciem, wcale nie sztuczna inteligencja, będąca „ekspertem” we wszystkich dziedzinach, jest najszybciej rozwijana pod kątem praktycznego wykorzystania.
Czym jest ANI?
Obecnie pod tym względem przoduje trzeci podtyp ANI (Artificial Narrow Intelligence), czyli AI wyspecjalizowana tylko w wąskim zagadnieniu. Przykłady to bazujące na technikach sztucznej inteligencji algorytmy: rozpoznawania twarzy, głosu i detekcji spamu w poczcie elektronicznej.

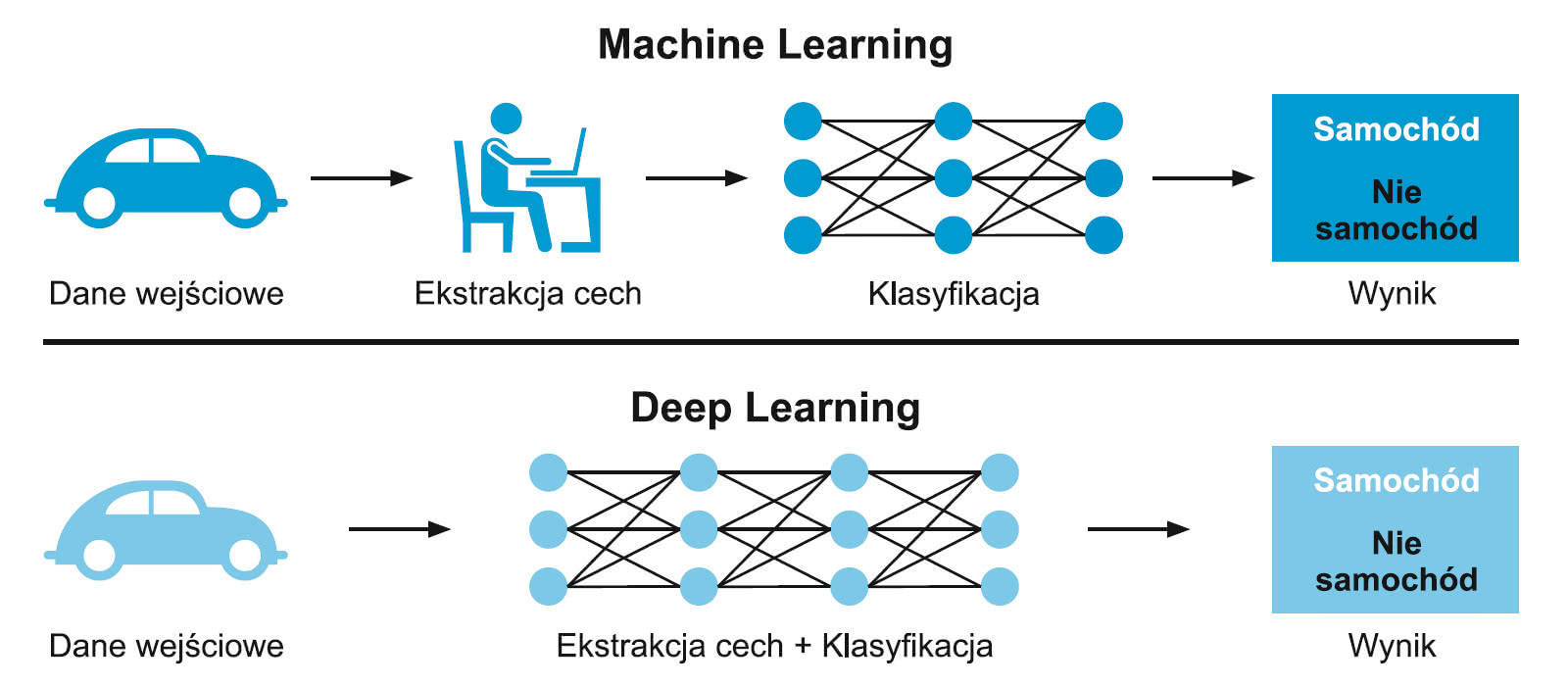
ANI wykorzystuje przeważnie uczenie maszynowe, które stanowi podzbiór technik AI. Jego celem jest zdobywanie umiejętności lub wiedzy z doświadczenia, czyli ich syntezę na podstawie danych historycznych. Praktycznie oznacza to, że w przeciwieństwie do „zwykłych” algorytmów, które opierają się na zestawach reguł sformułowanych za pomocą instrukcji if/then i warunków, w uczeniu maszynowym algorytm uczy się klasyfikowania danych wejściowych na podstawie ich próbek. Najlepiej wyjaśnić to na przykładzie.
Załóżmy, że potrzebny jest program, który będzie rozpoznawać konkretną literę napisaną odręcznie. Tradycyjnie w tym celu powinno się stworzyć algorytm sprawdzający, które piksele są jasne, a które ciemne i czy te ze sobą w siatce sąsiadujące układają się we wzory zdefiniowane dla danego znaku, uśredniające różne sposoby jego odręcznego zapisu. W implementacji uczenia maszynowego natomiast algorytmowi uczącemu się prezentowane są rzeczywiste dane. W tym przypadku są to próbki zapisu odręcznego szukanej litery oraz różnych innych. Na podstawie pierwszych uczy się on, czego ma szukać, a drugich – co powinien odrzucić. Im więcej danych w ten sposób przetwarza, tym staje się dokładniejszy.
Uczenie maszynowe (Machine Learning, ML) to rozległa dziedzina. Wyróżnić w niej można wiele podzbiorów nauk i różnych technik. Przykładowa klasyfikacja wyróżnia uczenie maszynowe: nadzorowane (Supervised Learning, SL), nienadzorowane (Unsupervised Learning, UL) oraz przez wzmacnianie (Reinforcement Learning, RL).
Uczenie maszynowe nadzorowane
Większość praktycznych implementacji uczenia maszynowego wykorzystuje tytułową technikę. W uczeniu nadzorowanym chodzi o to, aby dysponując zmienną wejściową x i zmienną wyjściową y, znaleźć funkcję określającą zależność pomiędzy nimi (odwzorowującą, mapującą), czyli y = f(x).
Celem jest jej jak najdokładniejsze przybliżenie, żeby na podstawie nowych danych wejściowych (x) można było przewidzieć zmienne wyjściowe (y). Nazwa tej techniki wzięła się stąd, że proces uczenia się algorytmu na podstawie zbioru danych treningowych jest nadzorowany trochę tak, jak nauka dzieci w szkole odbywająca się pod okiem nauczyciela – znane są prawidłowe odpowiedzi, algorytm iteracyjnie w oparciu o dane treningowe przedstawia swoją wersję odpowiedzi i jest poprawiany do czasu, aż osiągnięty zostanie zakładany poziom zgodności.
W uczeniu maszynowym nadzorowanym wyróżnia się dwie grupy zadań: klasyfikację (classification) oraz regresję (regression). W pierwszej zmienną wyjściową jest kategoria, przykładowo: „biały” albo „czarny”, „chory” lub „zdrowy”, „prawidłowy” albo „nieprawidłowy”. W regresji z kolei jest to liczba rzeczywista.
Uczenie maszynowe nienadzorowane
W tytułowej podgrupie uczenia maszynowego dysponujemy wyłącznie danymi wejściowymi (x), nie są jednak dostępne odpowiadające im zmienne wyjściowe. Celem nienadzorowanego uczenia jest zatem odkrycie i zamodelowanie struktury lub rozkładu danych, które pozwoliłyby się o nich więcej dowiedzieć. W przeciwieństwie do uczenia nadzorowanego nie ma w tym przypadku ani prawidłowych odpowiedzi, ani mechanizmu korygującego, z czego wzięła się nazwa tej techniki.
W uczeniu maszynowym nienadzorowanym także wyróżnia się dwie kategorie zadań: grupowanie (clustering) i powiązanie (association). W pierwszych należy w zbiorze danych znaleźć wspólne cechy pozwalające na ich zaklasyfikowanie do określonej grupy. Przykładem jest grupowanie klientów według ich decyzji zakupowych. W zadaniu powiązania z kolei w takim przypadku można by odkryć zależność, według której osoby, które kupują produkt A, zazwyczaj kupują również produkt B.
Większości zagadnień, w rozwiązywaniu których wykorzystuje się uczenie maszynowe, nie można jednak łatwo podzielić na te predysponowane do zastosowania w ich przypadku tylko techniki nadzorowanej lub wyłączenie nienadzorowanej. Wówczas konieczne jest podejście mieszane. Przykładem jest uczenie częściowo nadzorowane (Semi Supervised).
Uczenie częściowo nadzorowane i samonadzorowane
Pierwszą z tytułowych technik wykorzystuje się w sytuacji, kiedy większa część danych treningowych nie jest scharakteryzowana. Przykładem jest archiwum zdjęć, w którym tylko niektóre z nich są podpisane, na przykład pies, kot, człowiek, a obiekty na pozostałych nie są zidentyfikowane. W praktyce jest to częste podejście, ponieważ etykietowanie jest kosztowne i czasochłonne, szczególnie jeśli wymaga wiedzy eksperckiej, natomiast nieoznakowane dane są tanie, łatwe do zbierania i przechowywania. W uczeniu częściowo nadzorowanym celem jest, aby spożytkować wszystkie dostępne informacje, oznaczone i nieopisane. W tym celu korzysta się najpierw z metod uczenia nienadzorowanego, jak grupowanie. Po rozpoznaniu wzorców i struktur danych, w oparciu o metody uczenia nadzorowanego, można nadać etykiety danym nieoznakowanym. W ten sposób uzyskuje się komplet opisanych danych treningowych, umożliwiający znalezienie funkcji mapującej. Uczenie częściowo nadzorowane sprawdza się m.in. w dziedzinach: widzenia maszynowego, przetwarzania języka naturalnego, rozpoznawania mowy.
Kolejny przykład podejścia hybrydowego to uczenie samonadzorowane (Self Supervised). W tym przypadku algorytmy uczenia nadzorowanego służą do rozwiązywania zadania alternatywnego (pomocniczego), którego wynikiem będzie model, wykorzystywany następnie do rozwiązania oryginalnego problemu.
Co wyróżnia uczenie przez wzmacnianie?
Z kolei w uczeniu przez wzmacnianie algorytm eksploruje nieznane środowisko, by osiągnąć zadany cel. Proces ten nie jest nadzorowany ani nie są dostępne dane treningowe – te należy dopiero pozyskać, zbierając doświadczenia przez interakcję z otoczeniem i obserwację jego reakcji. Optymalnego zachowania w danym środowisku trzeba się nauczyć metodą prób i błędów, w oparciu o wskaźniki sukcesu, krótko- lub długoterminowe, wtedy gdy wynik jest nieznany, dopóki nie zostanie wykonana duża liczba sekwencyjnych działań.
To, co zasadniczo wyróżnia uczenie przez wzmacnianie na tle innych algorytmów uczenia maszynowego, to: koncentracja na problemie jako całości i możliwość adaptacji do zmian w środowisku. Dzięki temu ma zastosowanie do wielu złożonych problemów, których nie można rozwiązać za pomocą technik uczenia nadzorowanego ani nienadzorowanego. Jest też najbliższe silnej sztucznej inteligencji, gdyż pozwala zrealizować długoterminowe cele przez autonomiczne eksplorowanie różnych możliwości. Uczenie przez wzmacnianie znajduje zastosowanie m.in. w planowaniu ścieżek robotów, w którym zadaniem tej maszyny jest znalezienie najkrótszej i bezkolizyjnej drogi między dwoma lokalizacjami oraz w pojazdach autonomicznych.
Czym jest głębokie uczenie?
Tak jak uczenie maszynowe jest podzbiorem sztucznej inteligencji, tak głębokie uczenie (Deep Learning) to podgrupa uczenia maszynowego. Poświęca mu się ostatnio dużo uwagi, ponieważ zapewnia wyniki, które wcześniej nie były osiągalne, co przypisuje się temu, że inspiracją w jego implementacji jest ludzki mózg, a dokładniej sposób, w jaki są w nim zorganizowane połączenia synaptyczne pomiędzy neuronami. Dzięki temu algorytmy głębokiego uczenia poddają ciągłej analizie dane w sposób podobny do tego, w jaki człowiek wyciąga wnioski, efektywniej niż standardowe algorytmy uczenia maszynowego.
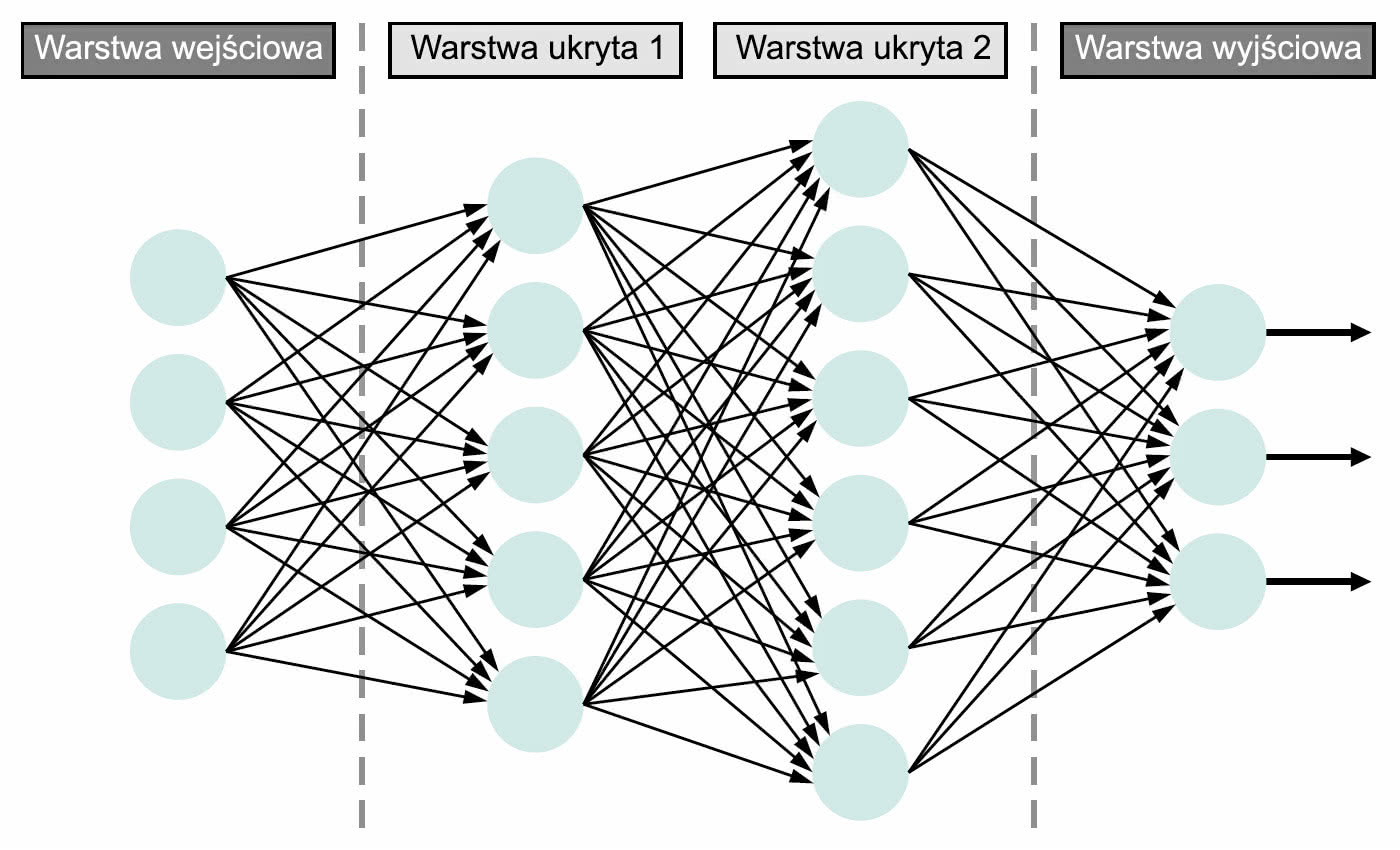
By to osiągnąć, w głębokim uczeniu wykorzystuje się warstwową strukturę algorytmów, tzw. sztuczną sieć neuronową (Artificial Neural Network, ANN), która samodzielnie uczy się oraz podejmuje decyzje. Przykład ANN przedstawiono na rysunku 1. Skrajna lewa warstwa nazywana jest wejściową, a skrajna prawa wyjściową. Środkowe to z kolei warstwy ukryte, wykorzystywane w wewnętrznych obliczeniach. Im więcej ukrytych warstw ma sieć między warstwą wejściową a wyjściową, tym jest ona głębsza. Generalnie każda sieć ANN z co najmniej dwiema ukrytymi warstwami jest określana jako głęboka sztuczna sieć neuronowa.
Sieci neuronowe z bliska
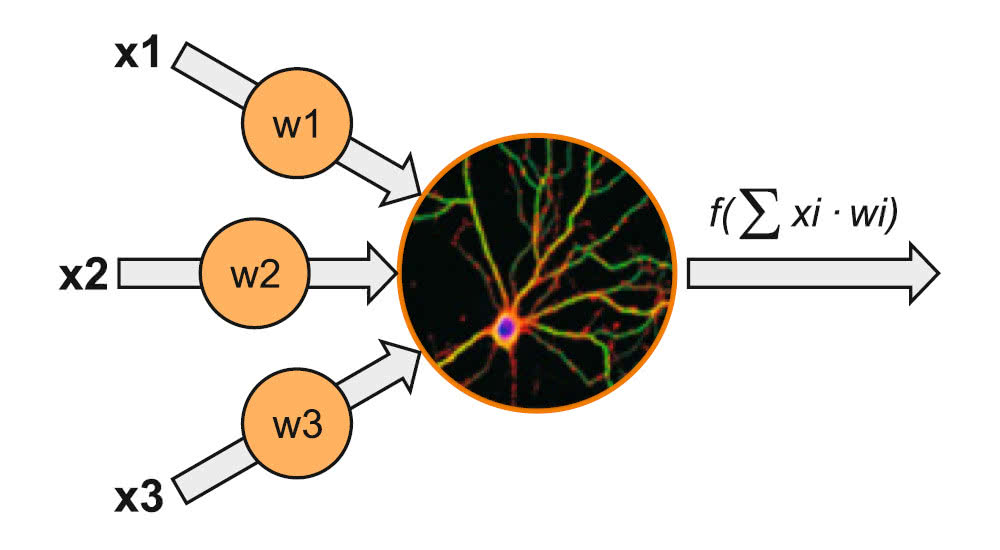
Najprostszy model ANN składa się z pojedynczego neuronu (perceptronu) (rys. 2). Suma ważona jego wejść, które w neuronie biologicznym byłyby dendrytami, jest argumentem funkcji. Jej wynik z kolei jest odpowiednikiem aksonu neuronu biologicznego. Pojedyncze neurony można ułożyć jeden na drugim, tworząc warstwy, które następnie umieszcza się obok siebie, żeby sieć była głębsza. Połączeniom pomiędzy poszczególnymi neuronami również przypisywane są wagi.
Przez tę wartość przemnażane jest wyjście jednego neuronu, przekazywane jako wejście drugiego, z którym ten pierwszy jest połączony. W procesie uczenia się sieci na danych treningowych te wagi są korygowane tak, aby zmniejszyć liczbę popełnianych błędów.
To, co wyróżnia sieci neuronowe z mechanizmem głębokiego uczenia, to doskonalenie w miarę przetwarzania nowych informacji, szybsze, im większa jest dana struktura, inaczej niż w tradycyjnych algorytmach uczenia maszynowego. W ich przypadku bowiem osiągany jest punkt, przy którym dopływ nowych danych treningowych nie prowadzi już do poprawy wyników.
Głębokie uczenie w praktyce
Najlepiej jest wyjaśnić tytułowe rozwiązanie na przykładzie. W tym celu przedstawiamy możliwą implementację głębokiego uczenia w zadaniu rozpoznawania znaków drogowych, którą można wykorzystać w autonomicznych pojazdach. W pierwszym kroku ANN powinna wyodrębnić wyróżniające się cechy znaku, który ma się nauczyć rozróżniać. Na obrazie mogą to być: krawędzie, punkty, kolory, obiekty. W tym celu przykładowo pierwsza warstwa ukryta sieci neuronowej powinna nauczyć się wykrywać krawędzie, następna rozróżniać kolory, a ostatnia wykrywać konkretny kształt. Po zasileniu danymi treningowymi algorytm głębokiego uczenia, ucząc się na własnych błędach, w końcu byłby w stanie rozpoznawać różne znaki drogowe.
Podsumowując, to co wyróżnia głębokie uczenie jako podzbiór uczenia maszynowego, to: struktura sztucznych sieci neuronowych, ograniczona potrzeba interwencji człowieka, dzięki zdolności do samodzielnej ekstrakcji cech i samouczenia się oraz większe wymagania dotyczące danych – dla porównania: uczenie maszynowe działa typowo z tysiącem punktów danych, zaś uczenie głębokie często z milionami. Chociaż pokazuje to ogromny potencjał tej techniki, wskazuje także główne powody, dla których dopiero niedawno jej implementacja stała się możliwa: wcześniejszy brak dostępności danych i mocy obliczeniowej odpowiadających potrzebom ANN.
Postęp w tym zakresie nastąpił dopiero razem z rozwojem technologii Big Data, infrastruktury przetwarzania w chmurze oraz mocy obliczeniowej procesorów i pojemności pamięci. Dzięki temu czas szkolenia ANN zaczął ulegać sukcesywnemu skracaniu z tygodni do godzin.
Uczenie transferowe
Prawdziwym przełomem było jednak wykorzystanie w głębokim uczeniu uczenia transferowego (Transfer Learning, TL). W skrócie w technice tej naukę nowego zadania usprawnia się przez transfer wiedzy z innego, powiązanego, którego już się nauczono. Najłatwiej wyjaśnić to przez analogię do tego, jak ludzie uczą się na przykład jazdy na rowerze. Początki są zwykle trudne i „złapanie” podstaw wymaga sporo czasu na nauczenie się, jak utrzymać równowagę, skręcać lub hamować. Kiedy jednak już te umiejętności posiądziemy i nabierzemy wprawy, a za jakiś czas zechcemy się nauczyć jeździć na motocyklu, tym razem nie będziemy już musieli zaczynać od zera. Dzięki temu nauka utrzymywania równowagi czy używania hamulców pójdzie nam już dużo łatwiej i szybciej, ponieważ wykorzystamy umiejętności zdobyte w czasie nauki jazdy na rowerze. Analogicznie dość łatwo algorytm, który nauczył się rozpoznawać psy, można nauczyć rozpoznawania kotów, przez przeniesienie między nimi pewnych abstrakcyjnych pojęć. W praktyce polega to na tym, że nauka nowego zadania odbywa się przy użyciu wstępnie wytrenowanych modeli, które w przeciwieństwie do tych w „zwykłym” uczeniu maszynowym są ogólne, a nie szczegółowe.
Uczenie transferowe niesie za sobą dwie zasadnicze korzyści, które wpłynęły na spopularyzowanie się głębokiego uczenia. Są to: zwiększenie szybkości uczenia dzięki temu, że algorytm musi się nauczyć tylko rzeczy „nowych”, specyficznych dla danego zadania, oraz zmniejszenie ilości wymaganych danych treningowych.
Doprowadziło to do wdrożenia technik sztucznej inteligencji w aplikacjach, które jeszcze kilka lat temu pozostawały w sferze fikcji w książkach i filmach. Przykładem jest interakcja głosowa człowiek-maszyna, którą pod strzechy wprowadziły inteligentne głośniki oraz aplikacje asystentów głosowych, jak Siri firmy Apple, Alexa Amazona, Cortana Microsoft u czy Google Assistant.
Interfejsy głosowe wykorzystują technikę NLP (Natural Language Processing). NLP umożliwia maszynom przetwarzanie i rozumienie tekstu i słów. Jest to interdyscyplinarna technika, łącząca lingwistykę obliczeniową (oparte na regułach modelowanie języka ludzkiego) z modelami statystycznymi, uczeniem maszynowym oraz głębokim uczeniem.

AI w praktyce – czym jest NLP?
Zdolność rozumienia tekstu pisanego i mówionego jest u ludzi naturalna, natomiast implementacja tego w maszynach jest wyzwaniem. Wynika to stąd, że język, za pośrednictwem którego się komunikujemy, jest pełen niejasności, powodujących, że trudno jest napisać program, który przewidywałby wszystkie możliwości interpretacji. Przykładami takich są: homonimy, czyli identyczne frazy mające różne znaczenia, homofony, czyli różne słowa wymawiane tak samo, sarkazm, idiomy, metafory, modyfikacje struktury zdań.
Zadanie przetwarzania i rozumienia tekstu/słów jest dzielone na etapy. W komunikacji werbalnej pierwszym jest rozpoznawanie mowy, polegające na jej zamianie na tekst. Jest ono wymagane w każdej aplikacji, która wykonuje polecenia głosowe albo odpowiada na pytania. Największą trudność na tym etapie sprawia różnorodność sposobów, w jaki ludzie rozmawiają (szybko, niewyraźnie, z akcentem, z różną intonacją).
W następnym kroku określane są zwykle części mowy na podstawie użycia i kontekstu słów albo fragmentów tekstu. W przypadku wyrazów o wielu znaczeniach w procesie analizy semantycznej trzeba wybrać to, które ma największy sens w danym przypadku. Często należy również określić, czy i kiedy różne słowa odnoszą się do tego samego. Zaawansowane aplikacje mogą oprócz tego wymagać rozpoznania nastawienia i emocji mówiącego.
Jak działają RNN?
W zadaniach NLP wykorzystuje się często zaliczane do kategorii algorytmów głębokiego uczenia rekurencyjne sieci neuronowe (Recurrent Neural Networks, RNN), które sprawdzają się w tym zastosowaniu dzięki możliwości przetwarzania danych sekwencyjnych i o różnej długości. Te są powszechne w zadaniach NLP, a właściwa interpretacja mowy i tekstu pisanego zależy od możliwości przetwarzania słów w kolejności, która determinuje znaczenie całości, a zarazem odwoływania się do tych poprzednich, by zrozumieć/przewidzieć te po nich następujące.
Rekurencyjne sieci neuronowe najlepiej wyjaśnić przez zestawienie z sieciami neuronowymi ze sprzężeniem do przodu (Feed-Forward Neural Networks, FFNN). Nazwy obu charakteryzują sposób, w jaki przekazują one informacje.
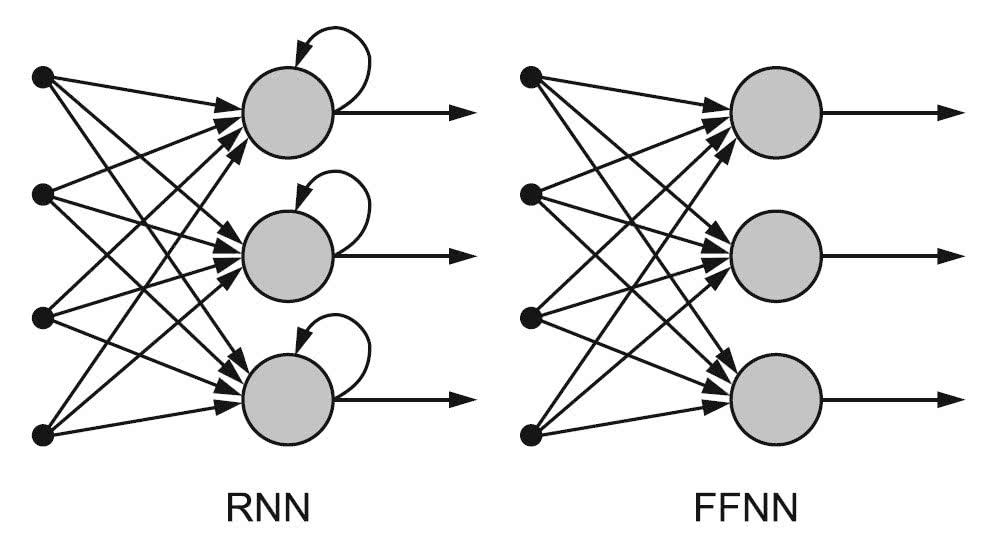
W FFNN odbywa się to wyłącznie w jednym kierunku – od warstwy wejściowej, przez ukryte, do warstwy wyjściowej, nigdy dwa razy przez ten sam węzeł. Tego typu sieci nie zapamiętują danych wejściowych ani nie porządkują ich w czasie. W RNN tymczasem dane krążą w pętli. To znaczy, że przy podejmowaniu decyzji pod uwagę brane są bieżące dane wejściowe, jak również wiedza, którą pozyskano wcześniej. Różnice w przepływie informacji w RNN a FFNN przedstawia rysunek 4.
RNN mają zatem pamięć krótkotrwałą (można ją wydłużyć). Dzięki temu jeżeli na przykład FFNN przetwarza słowo „szkoła” litera po literze, będąc przy „k”, nie pamięta już o „s” ani „z”, przez co nie może przewidzieć, jaka litera będzie następna. RNN tymczasem zapamiętuje kolejne, dzięki zapętlaniu wyjścia, łącząc najbliższą przeszłość z teraźniejszością. Oznacza to też, że macierz wag jest przypisywana zarówno bieżącym, jak i poprzednim danym wejściowym. Ponadto RNN mogą mapować jedno wejście do wielu wyjść, wiele do wielu (przydatne w tłumaczeniach) i wiele do jednego (wykorzystywane w klasyfikacji głosu).
Podsumowanie
Już pobieżne przedstawienie teorii sztucznej inteligencji dowodzi, jak szeroka i abstrakcyjna ta dziedzina może się wydawać osobom, które nie mają specjalistycznej wiedzy w tym zakresie. Pocieszające jest to, że aby rozpocząć swoją przygodę z tą technologią, niekoniecznie trzeba być ekspertem, dostępnych jest bowiem wiele narzędzi i bibliotek przeznaczonych do uczenia maszynowego, które pozwalają na łatwe tworzenie modeli, bez zagłębiania się w trudne szczegóły implementacji poszczególnych algorytmów. Warunkiem skorzystania z nich jest umiejętność programowania w języku Python, który jest dominującym językiem programowania w uczeniu maszynowym. Przykładami najpopularniejszych są TensorFlow (https://www.tensorflow.org) i PyTorch (https://pytorch.org).
Monika Jaworowska























